前言
LSM-Tree,全称The Log-Structured Merge-Tree(日志结构合并树)。
Log-Structured源自Ousterhout和Rosenblum在1991年发表的经典论文<<The Design and Implementation of a Log-Structured File System >>,这篇论文提出了一种新的磁盘存储管理方式,在这种结构下,针对磁盘内容的所有更新将会被顺序地写入一个类日志的结构中,从而加速文件写入和回收速度。该日 志包含了一些索引信息以保证文件可以快速地读出。日志会被划分为多个段来进行管理。这种方式非常适合于存在大量小文件写入的场景。
The Log-Structured Merge-Tree (LSM-Tree)就是设计用于来为那些长期具有很高记录更新(插入或删除)频率的文件来提供低成本的索引机制。LSM-Tree通过使用某种算法,该算法会对索引变更进行延迟及批量处理,并通过一种类似于归并排序的方式联合使用一个基于内存的组件和一个或多个磁盘组件。
LSM-Tree相关概念
索引组件
LSM-Tree由两个或多个类树的数据结构组件构成。一个两组件的LSM-Tree如下所示: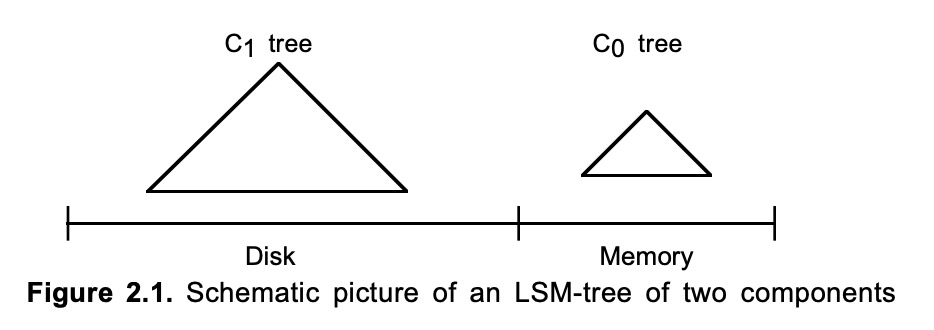
其中,C0-Tree驻留在内存中,而C1-Tree保存在磁盘上。
C0/内存组件
C0并不一定需要B树结构,因为C0不会持久化到磁盘中(或者说在使用C0树的过程中永远不会从磁盘中读取)。因此一棵AVL(平衡二叉搜索树)就可以满足需求,但依然需要保持插入节点的顺序。
当C0增长到它的阈值大小时,它会从最左边的一系列记录开始删除节点。
C1/磁盘组件
C1具有一个类似B树的目录结构,这种结构可以在牺牲一定CPU效率的前提下减少树的高度,从LSM-Tree中体现出来的就是减少磁盘IO的开销,这也是LSM-Tree最大的优点。
Q:为什么采用B树或者类似B树的目录结构呢?
A:为了将叶子节点按顺序排序,使的叶子节点的数据是连续的,减少磁盘臂的移动开销。
每个磁盘组件都是由以B树类型的结构组织的page-sized的节点组成,同时在根节点下的各层的节点都是按照key的大小顺序排列的,同时这些节点又会被放置到mutil-page block中。
它的意思是B树中的多个节点组成一个mutil-page block结构,在B树中可以获取到这个mutil-page block结构,然后就可以直接获取到这个mutil-page block下所有的节点,这样的好处就是在执行rolling merge的时候不需要重建检索一遍B树,而是通过遍历mutil-page block来批量获取节点。
multi-page block
一个抽象的概念,在LSM-Tree中,每条数据的索引在基于磁盘的组件中表现的就是B树的节点。多条索引记录组成mutil-page block。结构图如下:
在大多数情况,每个mutil-page block都装满了节点,但是也有些情况一个multi-page block只有少数节点组成,这个节点通常是上次rolling merge所合并的最后一个节点,因为受到删除操作的影响,最终进入filling block的数据量大小是不可控的。
emptying block
一组合并前所有节点组成的队列,每当进行一次合并后将其中的节点抛出。
filling block
完成数据合并后的最终结果,其中的数据是连续的,当它被填满后会被刷入磁盘中,写入时会在磁盘中新开辟存储空间,并不会覆盖旧的数据。这是为了出现异常时快速恢复
rolling merge
LSM-Tree中的C0存在内存中,而内存大小的成本是很大的,因此当C0的大小达到一定阈值后要被持久化到磁盘中,在LSM-Tree中,C0在持久化到磁盘前需要和C1的数据进行一次合并,这个过程就被成为rolling merge。
在这个过程中会将C0的部分或者全部数据删除并合并到C1中。
我们可以把整个两组件LSM-tree的rolling merge过程想象成一个具有一定步长的游标循环往复地穿越在C0和C1的键值对上,不断地从C0中取出数据放入到磁盘上才C1中。该rolling merge游标在C1树的叶节点和更上层的目录级都会有一个逻辑上的位置。
插入、删除、查询流程
插入
当数据插入的LSM-Tree的时候,它会执行两个操作:将其追加写入一个特殊的日志文件中用于异常/重启恢复;将其加入C0中。
当C0大小达到阈值的时候进行rolling merge,将C0的一部分数据移入C1中。
删除
当某一个记录要被删除时,如果目标索引不在C0中,则在C0中创建这个索引并加上删除标记,后续如果有其他用户需要对索引进行查询或者更新操作就可以直接返回,而不用在磁盘中查询。
实际的删除操作并不会立刻生效,而是会在C0记录中添加一条删除记录,这条记录会随着rolling merge往大的组件移动,一旦遇到对应的要删除的数据对象则执行数据清除工作。
如果要对原数据进行修改,在LSM-Tree中可以看成两条连续的记录,分别是删除、添加。
之所以要这样是因为有些更新操作会修改数据的ID,而不是其他数据,这样操作的后果就是目录中针对该数据的索引需要变更,而为了单条数据去扫描整个目录是十分愚蠢的,因此将这种更新操作转化为连续的两步删除与添加操作。
断言式删除
这是LSM-Tree中的批量删除的方式,它会在记录中添加比如:删除创建时间超过20天的记录这样的断言,当这条断言随着rolling merge移动到大的组件中时,那些符合条件的被载入内存的数据将会被清除。
查询
在执行等值匹配查询时,磁盘组件Ci的一个节点可能是存在于单独的一个内存页中,或者是通过它所在的muti-page block而缓存在内存中。
当在LSM-Tree中进行精确匹配查找或者随机查找时,步骤如下:
- 首先会到C0中查找所需的那个值或者域
- 如果C0中没有结果,则从C1中查找
与B树相比,这样的查找方式在一定条件下会有额外的IO开销与CPU开销,因为LSM-Tree的查找需要经过内存与磁盘。但是这两步简单的操作可以有很多优化方式:
- 如果生成逻辑可以保证索引值时唯一的,比如时间戳。则一个匹配查找已经在一个早期的Ci组件中找到的时候就可以宣告完成。因为越早的组件它的数据就越新,虽然旧的组件也会有这条数据,但那是已经过期的了。
- 如果查询条件里使用了最近时间戳,那么可以让那些查找到的值不要向最大的组件中移动,因为这些组件通常时间比较前。一个查询操作可能需要随着rolling merge一直传播到最大的组件,但如果在查询条件中加上时间限制,由于LSM-Tree的记录都是顺序的,因此在监测到有记录的时间戳已经超过查询条件后就可以直接结束查询。
- 当merge扫描到(Ci, Ci+1)对时,可以将最近常访问的值继续保留在Ci中,因为merge完成后原始数据会在内存中保留一段时间,这短时间内可以为常用数据提供快速查找
第三点在短期事务UNDO日志中就有所使用,对于短期事务,在中断发生时通常都是针对相对近期的数据的访问,这样大部分的索引就都会仍然处于内存中。
- 通过记录每个事物的启动时间,就可以保证所有最近的t0秒内发生的事物的所有日志都可以在C0中找到,而不需要磁盘访问。类似于第2条的优化方式,也是按照时间将查询的范围缩小。
long-latency find
对于那些需要等待很长时间的查询操作来说,通过向C0中插入一个find note entry,当它被移入更大的组件中时如果遇到符合条件的数据则会记录下来,随着rolling merge的进行,查询也会生效,直到到达最大组件,本次long-latency find所对应的那些匹配的ID记录就生成完毕了。
rolling merge
通常,一个具有C0、C1…Ck个组件大小不断增长的LSM-Tree,其中C0组件是放在内存中,其他组件都是在磁盘中驻留。当Ci-1超过阈值时,会由(Ci-1,Ci)之间的异步的rolling merge过程负责将记录从小的组件移到更大的组件中。
当C0的大小达到一定阈值的时候会进行异步rolling merge,此时将C0中的部分或全部数据与C1的节点进行合并,然后将接入重新写入C1。当C1大小达到一定阈值后也会启动rolling merge操作将数据转移到C2中。以此类推。
每次进行rolling merge的时候会处理多个操作:将B树中针对单条操作的IO开销通过批处理进行分摊。
rolling merge的执行顺序如下:
- 读取一个包含了C1-Tree中叶子节点的multi-page block,将C1的一系列记录加载进缓存中
这里的multi-page block就是前面的emptying block,因为这些数据会和C0的叶子节点进行合并。而合并的结果将会被保存在filling block中。
- 每次merge直接从缓存中以磁盘页的大小读取C1的叶子节点,将来自叶子节点的记录与从C0-Tree中拿到的叶子节点级的记录进行merge
- 在C1-Tree中创建保存merge结果的叶子节点,这些新的叶子节点会被放在C1的最右边
- 将新的节点刷入磁盘,这些信息会被放入新的磁盘位置,然后将C1的指针指向这个位置。
Ci树的变更如下: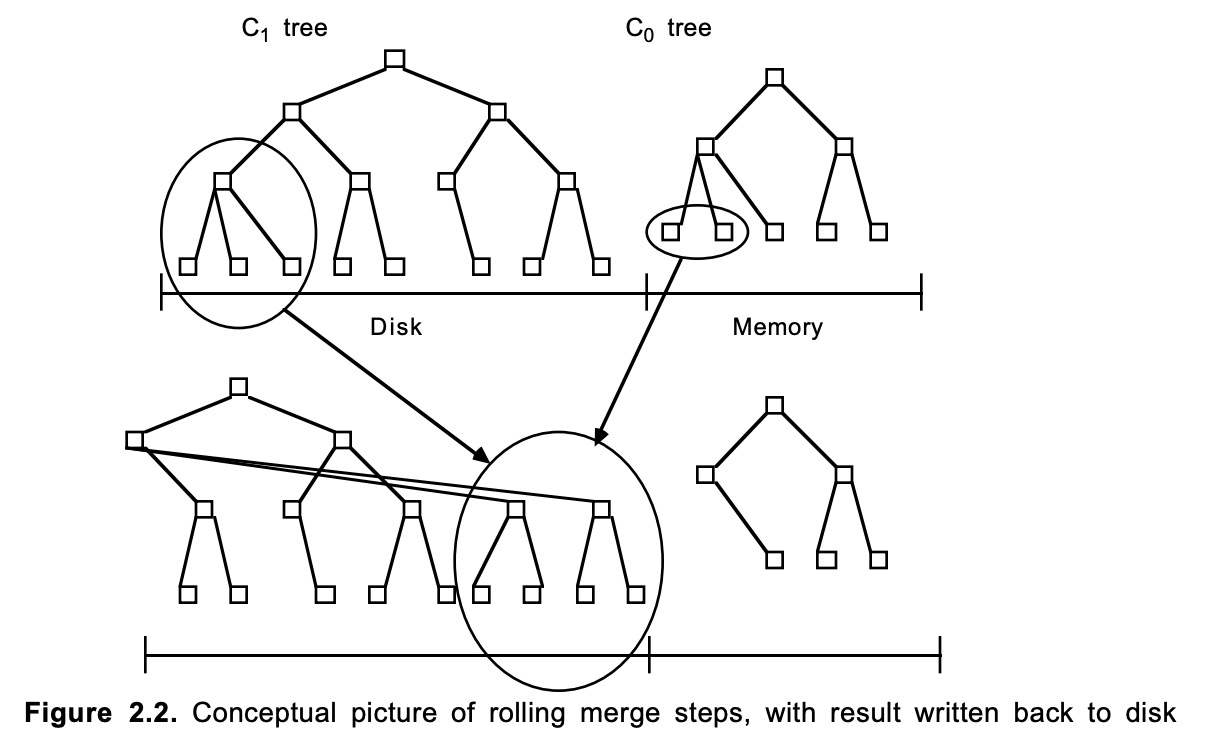
从图中可以看到,C1与C0合并之后原有的旧节点会被删除。但是在实际合并过程中这些节点的删除时间在新的节点被刷入磁盘后,在合并的时候并不会被删除,这是为了保证在合并时这些数据依然能对外提供服务。以及在合并时发生异常后的恢复工作。直到后续新增的数据足够多使的涵盖这些block的checkpoint过期后才能回收。否则提前回收的化如果要将LSM-Tree恢复到这些block还生效的时间点,恢复就会失败。
对于节点的删除,通常来说就是覆盖写。并不会执行物理删除,因为覆盖写的效率比随机写高很多 。
由于C1与C0的叶子节点都是顺序排序,因此在C1读取到中间的时候可能就知道C0中已经没有节点可以进行merge了,但是为了保持C1中叶子节点顺序,每次rolling merge都需要将C1整个读取一遍。因此一次rolling merge结束的标志是读取到C1的最大索引段。
这里的整个读取并不是说将C1一次性读取,而是将C1分批次读入内存中。
虽然在写入的时候是批处理,但是在进行合并的时候是以单个索引节点为单位。在此时会发生的情况如下:
- 首先会创建一个新的基于C1的子节点组件
- 从emptying block获取C1的一个索引节点
- 从C0中读取小于该索引或者跟这个索引是连续的数据将其合并并放入filling block中
- 如果C0中有关于删除C1这条记录的删除操作,则将其直接抛弃。这也是LSM-Tree中的删除操作
- 当filling block满了之后(达到C1节点的大小阈值)将其刷入磁盘中
每一次rolling merge,更大的组件中的数据量总是会发生变化,当它的组件大小超过阈值后也会触发rolling merge将其与下一个更大的组件合并。
从我学习java的角度出发,这种方式有点类似于JVM的垃圾回收机制,C0就是新生代、C1以及之后的更大的节点就是S0与S1、最大的组件就是老年代。
当然这有点牵强,因为数据在LSM-Tree的移动依据是创建时间,而对象在堆中的移动依据更大程度在于是否有被引用。
组件大小估算
估算组件大小主要影响因素有两个:磁盘IO开销与数据插入频率。具体推导过程点击此链接
如何处理并发
在任何情况下,所有未被锁住的Ci组件的节点都是可以始终被访问的,磁盘访问也可以执行以定位内存中的节点,即使该节点是正在进行rolling merge的muti-page block的一部分。
在考虑各种因素的情况下,LSM-Tree的并发要处理三个问题:
- 查询操作不能同时去访问另一个进程的rolling merge正在修改的磁盘组件的节点内容
- 针对C0组件的查询和插入操作也不能与正在进行的rolling merge的同时对树的相同部分进行访问
- 从Ci-1到Ci的rolling 的由表有时需要越过从Ci到Ci+1的rollinng merge的由表,因为数据从Ci-1移出速度 >= 从Ci移出的速率,这意味着Ci-1所关联的游标的循环周期要更快。因此无论如何,所采用的并发访问机制必须允许这种交错发生,而不能降至要求在交会点,一个进程必须阻塞在另一个进程之后。
第一个和第二个问题可以概括为:正在merge过程中发生修改或者合并的结果,在合并完成前不能被查询与插入操作“看到”。第三个问题在于数据从Ci-1移入Ci与Ci将数据移入Ci+1时,两个游标在扫描的过程中会发生交叉,如果都是查询还好,但是Ci-1移入的游标还负责将合并结果插入Ci中,这就要求在合并完成前新插入的数据不能被Ci到Ci+1的rolling merge游标“看到”,更严格来说,就算Ci-1的rolling merge完成,但是Ci的rolling merge还没完成的情况下,它依然不能看到合并的新节点。
节点是LSM-tree中用于避免基于磁盘的组件的并发访问冲突的加锁单位。正在因rolling merge而被更新的节点会被加上写锁,同时正在因查询而被读取的节点将会被加上读锁。有专门的目录机制用于解决死锁的问题。
由于C0存在内存当中,因此它的数据结构并没有特殊的要求。在2-3树的情况下,我们可以用写锁锁住一个包含了merge到C1中的某个节点的受影响的边界内的所有记录的(2-3)树目录节点下的子树;同时用读锁锁住查找操作所涉及的查找路径上的所有节点,这种不同类型的访问就是互斥的。
2-3树就是最简单的B树
无论是在内存中还是在磁盘上,在LSM-Tree中的所有组件的节点都是顺序排列的,那么在C0属于2-3树的情况下,在选取每一批参与rolling merge的multi-page block的时候,可以在2-3树中选取一个节点,以该节点为root节点的子树都是本次要被rolling merge的节点。那么,可以在这个节点上加上写锁;同时,在查找的时候,所有涉及的节点都要被加上读锁。不同类型的锁是互斥的。
当节点中的所有节点都已经参与rolling merge,且所有新节点都已经写入新的组件中之后才释放写锁;当被查找的叶子节点被扫描后就释放读锁,这样就能让一个更快的游标越过更慢的游标。
假设正在执行两个磁盘组件之间的rolling merge,将记录从Ci-1(又称为该rolling merge过程的内组件)移到Ci(又称为该rolling merge过程的外组件)。
游标在Ci-1的叶级节点中具有明确定义的内部组件位置,指向它即将向外迁移到Ci的下一个条目的位置,同时在Ci-1的更高层的目录上沿着到达该叶子节点的访问路径都有一个对应位置。同时在Ci组件的叶子节点与到达该叶子节点的访问路径中,该游标也有一个位置。在一次rolling merge过程中,游标会读取Ci-1与Ci中的待合并的节点,为了提供并发能力,通常这些节点都是批量地载入内存中并放置在emptying block中。当merge发生后会从emptying block中取出Ci-1与Ci的节点并执行合并,直到合并完成并刷入磁盘这段时间内都会对这些数据加上写锁。
锁的释放
- 读锁:一旦叶节点上的条目被扫描完了,就会释放
- 写锁:滚动游标使用的写锁会在合并到更大的组件后背释放
checkpoing与恢复
checkpoint
当新的记录被插入的LSM-Tree的C0组件后,它会在C0达到阈值后通过rolling merge刷入磁盘,在这期间系统发生异常并重启的话对于一些缓存在内存中的数据来说就是不安全的。
因此LSM-Tree也面临一个经典的恢复问题:重构那些已经存在于内存中的而在系统crash丢失的内容。
针对这些新记录的事务型插入日志已经被常态性地写出到一个顺序性的日志文件中,因此只需要简单地将这些插入日志(日志里包含了所有field的值插入记录所对应的RID)作为索引值恢复的基础即可。这种用于索引恢复的新方式必须内建到系统恢复算法中,同时它也会影响到对于这种事务型插入历史日志的存储空间回收时间,在恢复发生时回收会被延迟。
对于LSM-Tree来说,需要准确定义checkpoint的格式以及如何确定从顺序型日志中的哪里开始往下读取并回放日志。
在LSM-Tree中,在T0时刻要创建checkpoint,它会等待所有正在进行中的merge步骤,保证所有节点的写锁都被释放;然后将新纪录的插入延迟到checkpoint完成,此时没有C0中的读锁也不会被占用。然后通过以下步骤创建checkpoint:
- 将C0组件的内容写入到一个已知的磁盘位置;之后,针对C0组件的记录插入就又可以开始了,但是merge步骤将会继续被延迟
- 将所有磁盘组件在内存中的脏页flush到磁盘,这些其实就是磁盘组件位于内存的缓存数据。
- 创建一个具有如下信息的特殊的checkpoint日志:
- 日志序列号(Log Sequence Number,LSN0),即T0时刻最后插入的索引行
- 所有组件的根节点的磁盘地址
- 上面这些组件中的所有merge游标的位置
- 当前关于新的multi-page block的动态分配信息
当将C0写入磁盘后,不需要等其他步骤完成就可以恢复针对C0的插入,因此在创建checkpoint的时候暂停时间并不会很长;同时也会影响到新插入到C0的记录被持久化到磁盘的时间会有所延迟。
恢复
当系统崩溃恢复后会执行以下操作:
- 在日志中定位一个检查点;
- 将之前写入硬盘的C0和其它组件在内存中缓存的multi-page block加载到内存中;
- 将日志中在LSN0之后的部分读入内存,执行其中索引条目的插入操作;
- 读取检查点日志中硬盘部件(C1~Ck)的根的位置和合并游标,启动rolling merge,覆盖检查点之后的多页块
- 当检查点之后的所有新索引条目都已插入至LSM-tree且被索引后,恢复即完成。
一次checkpoint恢复后可以做到:复原C0的数据、复原磁盘组件在内存中的缓存、复原所有磁盘组件正在进行的merge步骤。最后一点包含了:所有组件所有merge游标的位置、所有组件merge过程中的emptying block与filling block信息。
在恢复过程中的一个细节是如何处理目录变化,在创建checkpoint的时候,当filling-page block满了并刷入内存后立刻更新磁盘目录树中的上级节点指针,使得所有刷入磁盘的目录数据都是merge完成后的新数据。当checkpoint创建后持久化到磁盘中的filling-page block很有可能未满,不过这没有关系,在恢复的时候会将这部分信息全部读入内存中,所要做的就是在filling-page block满了并写入磁盘后重新修改目录树的指针,将其指向这个磁盘位置即可。这个修改指针的操作实际上并没有多余的IO开销,他是随着merge的进行顺便修改。
相关阅读
- 防止死锁发生的目录锁机制:B树并发
- 用于事务隔离的key range锁:数据库系统的并发控制和恢复
- 关于phantom update的问题:Jim Gray and Andreas Reuter, “Transaction Processing, Concepts and Techniques”,Morgan Kaufmann 1992.
- 关于垃圾收集的问题:日志结构文件系统的设计与实现