本来是想了解第一次merge过程中memtable如何转化为sstable的,结果代码找错了一路看下来是讲如何进行level合并的。
会调用合并函数的接口如下:
- MakeRoomForWrite - 为写入腾出空间
- Get - 根据key查询数据
- Open - 根据name打开数据库
- RecordReadSample - 记录在指定内部密钥读取的字节样本。
为什么会这样安排我认为有两个方面:
- LevelDB这种基于LSM-Tree实现的数据库所应用的场景是写多读少的场景,因此上面这几个的操作不会太频繁,在其中加入合并操作对系统的影响较小。
- LSM-Tree的写入是追加写,它的写入效率是很高的,在极端情况下如果没有查询功能就是日志系统,这种情况下写入的效率跟存储结构关系不大,无论数据是采用何种方式存储的,它都是追加写。而查询操作为了保证效率就对数据结构有一定要求,这也是LSM-Tree分出多个不同组件的原因,本质是为了加快查询效率。
合并前的准备工作
Level合并涉及到文件的IO操作,这会极大程度地拖慢查询效率。因此在LevelDB中合并操作是在一个新线程中进行的。为合并任务开启线程并执行的功能交给env模块来实现,相关代码位于db_impl.cc的void DBImpl::MaybeScheduleCompaction()函数中。调用如下:1
env_->Schedule(&DBImpl::BGWork, this);
同时在这个方法中还对合并的前提进行校验:
通过注解看到,当一下情况发生的时候不执行合并:
- 正在合并
- 数据库正在被删除,即有了删除标记
- 数据库操作出现一个error,为了保证数据不会在error的情况下多次出错,禁止压缩。如果合并就意味着要将异常数据传递到其他Level块
- 没有需要压缩的数据,这里的数据在DBImpl中表现为imm_对象为空且当前是最新版本的数据
如果进入env_的Schedule可以看到C++的reinterpret_cast用法,这里主要是为了减少env模块与db模块的耦合程度。对于程序来说转换前后都是DBImpl对象,因此在对象转换过程中并不会出错.
2
3
4
5
6
7
8
9
void Schedule(void (*f)(void*), void* a) override {
return target_->Schedule(f, a);
}
//db_impl.cc
void DBImpl::BGWork(void* db) {
reinterpret_cast<DBImpl*>(db)->BackgroundCall();
}
由于压缩是在一个新的线程中进行,因此为了避免多线程之间数据的不一致性,在进入BackgroundCall之后还需要再加锁进行可行性检查,相关代码位于db_impl.cc文件的void DBImpl::BackgroundCall()函数中,主要部分如下:1
2
3
4
5
6
7
8
9MutexLock l(&mutex_);
assert(background_compaction_scheduled_);
if (shutting_down_.load(std::memory_order_acquire)) {
// No more background work when shutting down.
} else if (!bg_error_.ok()) {
// No more background work after a background error.
} else {
BackgroundCompaction();
}
相关概念
首先确定一个参数的名称:
- imm_:LevelDB中的已经写满并被设置为只读的memtable,等待持久化操作将其转换为sstable写入磁盘中。
Compaction介绍
首先确定LevelDB中对于合并的最终目的是为了消除那些重复记录以及将已被删除的数据清除。这个过程称之为Compact。
LevelDB的Compaction主要执行三种操作:
- 均衡各个level的数据,保证read的性能
- 合并delete数据,释放磁盘空间,因为leveldb是采用的延迟(标记)删除;
- 合并update的数据,例如put同一个key,新put的会替换旧put的,虽然数据做了update,但是update类似于delete,是采用的延迟(标记)update,实际的update是在compact中完成,并实现空间的释放。
这种做法与后面的InternalKey的设计相辅相成,只需要将对同一个key的最新操作放在集合之前,就可以快速得到这个key的最新值,而不用迭代所有针对这个key的操作。
根据上述,这种针对磁盘文件的Compation有三种模式:Manual Compaction,Size Compaction 和 Seek Compaction。
- Manual Compaction:是人工触发的Compaction,由外部接口调用产生,例如在ceph调用的Compaction都是Manual Compaction。
- Size Compaction:是根据每个level的总文件大小来触发,注意Size Compation的优先级高于Seek Compaction。
- Seek Compaction:每个文件的 seek miss 次数都有一个阈值,如果超过了这个阈值,那么认为这个文件需要Compact。
针对memtable的操作为一次minor Compaction。这个过程是将memtable持久化为sstable。
在DBImpl::BackgroundCompaction中体现了这几种不同Compaction执行的优先级。
最高的是minor Compaction:1
2
3
4if (imm_ != nullptr) {
CompactMemTable();
return;
}
其次是manual Compaction:1
2
3
4
5if (is_manual) {
//...
} else {
c = versions_->PickCompaction();
}
最后是size Compaction优先于seek Compaction。1
2
3
4
5
6
7if (size_compaction) {
//...
} else if (seek_compaction) {
//...
} else {
return nullptr;
}
这里可以看到对于一次Compact,是不能够执行多个多种Compaction的。
如果都在同一个合并任务中进行会发生什么情况呢?首先对于Minor Compaction来说它会将memtable转储为sstable,假设该sstable为level0,然后执行一次manual compaction,该行为至少会将level0与level1的数据进行合并。这样会导致三个问题:
- 单次Compact流程过长,虽然这个任务是在一个新的线程中进行的,但是依然会占用系统开销。在频繁插入的情况下会影响到主流程性能。
- 无法利用数据在Level0的时候对查询操作的提速,在LSM-Tree中,越靠后的组件文件其大小越大,检索时间越慢。
- 增加系统复杂度。memtable持久化为sstable与sstable合并到下一个Level文件之间有一个时间差,如果这个时间差内有查询操作需要到磁盘文件中查询,那么它要查询这个刚生成的sstable还是等待sstable合并到下一个Level之后再查询?
Minor Compaction
Minor Compaction函数为DBImpl::CompactMemTable(),是将immutable memtable持久化为sstable文件。触发条件是在数据写入LevelDB后会检查memtable的数据大小,如果超过options_.write_buffer_size(默认4MB)就会尝试执行Minor Compaction。
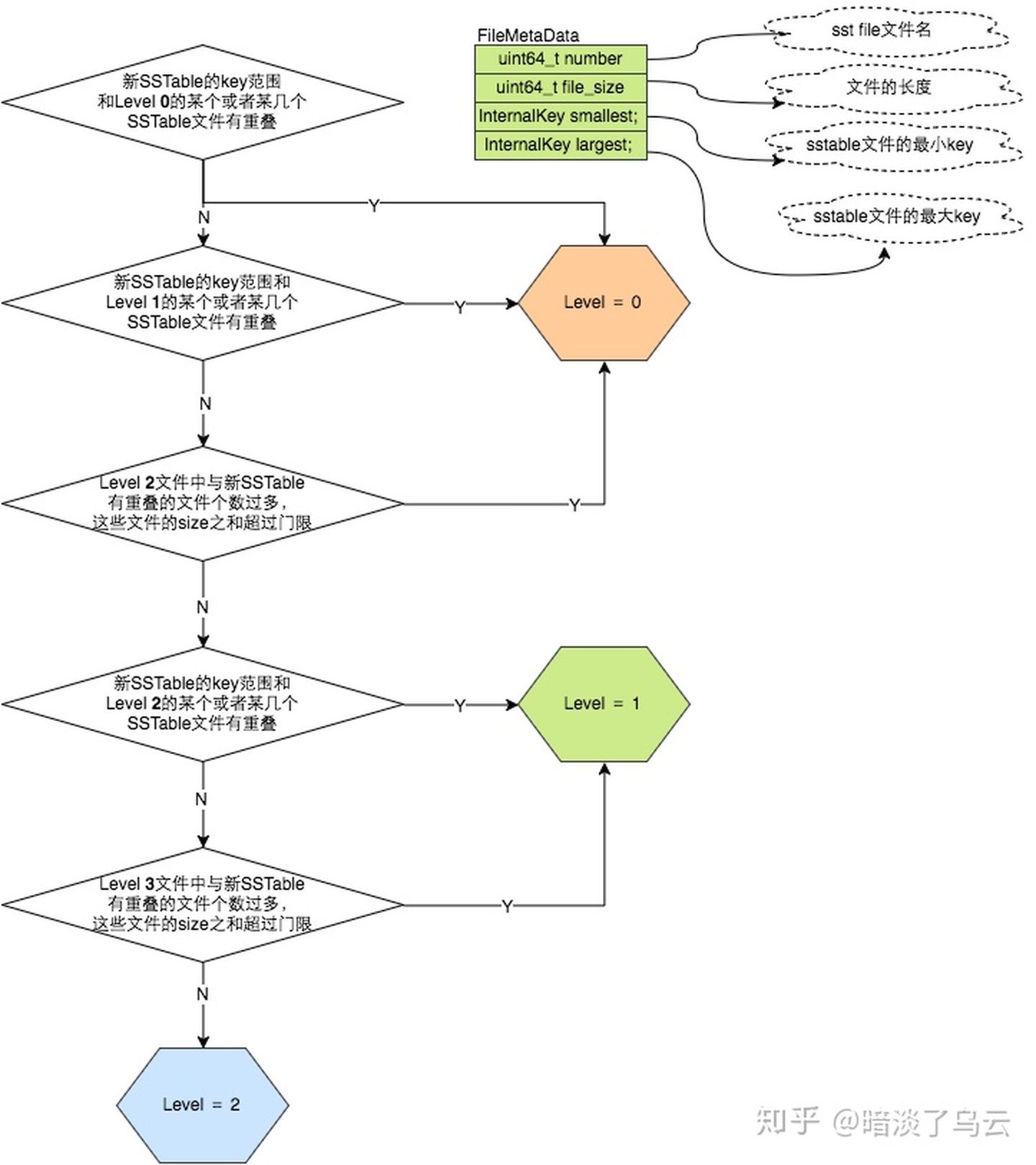
从理论上来说,每次memtable生成的sstable都应该位于level0。但在DBImpl::WriteLevel0Table函数中对level的赋值操作却是由PickLevelForMemTableOutput函数计算的。该函数的参数是生成的sstable的user key范围。当level0中有sstable跟这个范围重叠的时候就将新生成的sstable放置在level0,如果user key范围没有重叠,则将其往上推送。但是最高只能推送到level2,这个范围由kMaxMemCompactLevel控制。
如果level0文件生成过多,compaction IO与查找都会比较耗费时间;但如果将sstable推送过高,将导致查询时查询次数过多。因此在折中后将生成的sstabl推送的最高level就是2.
执行流程为:
- 将imm持久化为sstable
- 根据策略得到这个sstable所在的level
- 将这个sstable加入对应的level
磁盘Compaction
Manual Compaction
在DBImpl::CompactRange(const Slice* begin, const Slice* end)函数中可以手动配置发生合并时的行为。它的行为是对指定的key的范围的所有数据全部进行Compact。如果begin与end为空,则会对整个磁盘的所有SSTable进行Compact。
由于start与end不一定位于同一个SSTable,甚至不会位于同一层Level,因此在创建手动Compact的时候需要迭代所有Level并获取到进行Compact的最大Level。
在代码中开始检查的范围是从Level1开始而不是Level0。这里表明,即使是手动限制了Compact的范围,但依然要保持Compact的初衷:减少数据膨胀,消除重复垃圾数据。如果严格限制在给定的范围内,那么用户如果多次在高level上设置范围,那么产生最快的level0等sstable将长时间得不到压缩,这在LevelDB应对的写多读少的情境下会导致文件爆炸增加。且max_level_with_files默认为1也是表明即使范围位于level0,也会执行一次level0到level1的压缩以减少数据。
这里首次发现了
config::kNumLevels,点进去可以看到LevelDB针对LSM-Tree所做的配置与优化,包括level0的弹性数量限制、最高level限制、数据在单次compact中被推送的最高level限制等,每个参数都包含对应的注解。
得到最高level之后执行TEST_CompactMemTable()等待先前的压缩完成。?
然后进入DBImpl::TEST_CompactRange(int level, const Slice* begin, const Slice* end)函数。该函数的主要作用在于创建手动压缩对象ManualCompaction,该结构体的定义如下:1
2
3
4
5
6
7struct ManualCompaction {
int level;
bool done;
const InternalKey* begin;
const InternalKey* end;
InternalKey tmp_storage;
};
创建好ManualCompaction对象后调用MaybeScheduleCompaction函数开始进行压缩。
关于InternalKey
InternalKey是由key+MaxSequenceNumber+ValueTypeForSeek组成。其格式为| User key (string) | sequence number (7 bytes) | value type (1 byte) |。
sequence number的定义如下:
static const SequenceNumber kMaxSequenceNumber = ((0x1ull << 56) - 1);,可以看到其大小为7 bytes。
value type定义如下:kTypeValue = 0x1,针对1位的最小操作大小为1byte。
SequenceNumber是所有基于op log系统的关键数据,它唯一指定了不同操作的时间顺序。
把user key放前面的原因是针对同一个user key的所有操作可以看到sequenceNumber顺序连续存放。这样在进行合并的时候可以快速获取该user key最新的状态,而不用遍历所有操作。
Size Compaction
Size Compaction是levelDB的核心Compact过程,其主要是为了均衡各个level的数据,从而保证读写的性能均衡。
它的触发条件在代码中表现为:1
const bool size_compaction = (current_->compaction_score_ >= 1);
其中compaction_score_参数由Finalize()初始化,表示接下来的压缩level以及压缩score。当score小于1的时候表示当前level下的压缩并不是必须的。
在VersionSet::Finalize函数中,会计算每个level的大小并得到要进行压缩所要达到的最大level与score。
其中,level0与其他文件的计算并不一样。在LevelDB中通过限制levle0的文件数量而不是字节大小来调整level0的分布情况。主要原因在于:
- 对于较大的写入缓冲区,最好不要在level0进行频繁的Compact操作。因为level0的结构与memtable几乎相同,查询时效率比之后的sstable要高;且作为最新插入的数据,被立刻访问的概率比较大,因此避免频繁地Compactino操作阻碍查询效率。
- 在每次调用
Get函数时合并level0的文件,避免在level0单个文件较小时执行Compact操作。Compact操作涉及的IO操作比较频繁且对系统的影响较大,小文件level0频繁地Compaction有点得不偿失。
对于level0来说文件个数阈值kL0_CompactionTrigger = 4,则1
2//score = level0的文件个数 / 4
score = v->files_[level].size() / static_cast<double>(config::kL0_CompactionTrigger);
对于其他level,每个level都有一个阈值,此时score的计算如下:1
2
3
4//获取当前level下文件的总大小
const uint64_t level_bytes = TotalFileSize(v->files_[level]);
//score = 当前level下文件的总大小 / 阈值
score = static_cast<double>(level_bytes) / MaxBytesForLevel(options_, level);
所有level的阈值如下:
- 0: 10M(level 0可以忽略,其采用的是文件个数计算score)
- 1: 10M
- 2: 100M
- 3: 1000M ( 1G)
- 4: 100000M ( 10G)
- 5: 1000000M ( 100G)
Level6并不存在Compact,所以不存在阈值。
执行流程
首先计算的score值,可以得出 max score,从而得出了应该哪一个 level 上进行 Compact,获取操作如上。
然后分为两个大的步骤:选出本次Compact要进行合并的sstable;选出要合并到的level+1的sstable。假设计算出的level为n。
首先是第一部分:
在LevelDB上一次执行完Compact之后会保留上一次Compact操作的当前level n下的largest key。遍历给定level n中的所有sstable获取首个sstable中的largest key大于上次largest key的sstable。1
2
3
4
5
6
7
8for (size_t i = 0; i < current_->files_[level].size(); i++) {
FileMetaData* f = current_->files_[level][i];
if (compact_pointer_[level].empty() ||
icmp_.Compare(f->largest.Encode(), compact_pointer_[level]) > 0) {
c->inputs_[0].push_back(f);
break;
}
}
如果n为0,则遍历所有sstable并将有重叠的sstable加入Compact文件列表中,对于level0来说,所有的sstable都有可能存在重叠。1
2
3
4
5if (level == 0) {
InternalKey smallest, largest;
GetRange(c->inputs_[0], &smallest, &largest);
current_->GetOverlappingInputs(0, &smallest, &largest, &c->inputs_[0]);
}
然后是第二部分:
主要确定leveln+1中参与Compact的文件列表。
首先是计算出leveln中参数Compact的smallest与largest的key的范围。1
2InternalKey smallest, largest;
GetRange(c->inputs_[0], &smallest, &largest);
然后,根据计算出来的key范围,从leveln+1中获取范围重叠的sstable文件列表。1
current_->GetOverlappingInputs(level + 1, &smallest, &largest, &c->inputs_[1]);
最后计算当前的level n 和 n+1参与Compact的两个文件列表的总和,如果小于阈值kExpandedCompactionByteSizeLimit=50M,那么会继续尝试在level n中选择出合适的sst文件。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15if (expanded0.size() > c->inputs_[0].size() &&
inputs1_size + expanded0_size < ExpandedCompactionByteSizeLimit(options_)) {
InternalKey new_start, new_limit;
GetRange(expanded0, &new_start, &new_limit);
std::vector<FileMetaData*> expanded1;
current_->GetOverlappingInputs(level + 1, &new_start, &new_limit, &expanded1);
AddBoundaryInputs(icmp_, current_->files_[level + 1], &expanded1);
if (expanded1.size() == c->inputs_[1].size()) {
smallest = new_start;
largest = new_limit;
c->inputs_[0] = expanded0;
c->inputs_[1] = expanded1;
GetRange2(c->inputs_[0], c->inputs_[1], &all_start, &all_limit);
}
}
以上的代码位于version_set.cc的VersionSet::PickCompaction函数中。
最终,对于leveln的下一次压缩位置会在计算出本次压缩所涉及的文件范围后立刻得到并设置。这样当当前的key范围出现异常时,下一次的Compaction会在新的范围中进行,从而绕过错误数据。1
2compact_pointer_[level] = largest.Encode().ToString();
c->edit_.SetCompactPointer(level, largest);
Seek Compation
在levelDB中,每一个新的sstable文件,都有一个allowed_seek的初始阈值,表示最多容忍seek miss多少次,每个调用Get seek miss的时候,就会执行减1(allowed_seek–)。其中allowed_seek的初始阈值的计算方式为:1
2f->allowed_seeks = static_cast<int>((f->file_size / 16384U));
if (f->allowed_seeks < 100) f->allowed_seeks = 100;
LevelDB认为如果一个 sst 文件在 level i 中总是没总到,而是在 level i+1 中找到,那么当这种 seek miss 积累到一定次数之后,就考虑将其从 level i 中合并到 level i+1 中,这样可以避免不必要的 seek miss 消耗 read I/O。当然在引入布隆过滤器后,这种查找消耗的 IO 就会变小很多。
在源码中有详细介绍为何需要有这项机制。
假设:
- 一次寻道花费10ms
- 写入或读取 1MB 花费 10ms (100MB/s)
- 1MB 的压缩会产生 25MB 的 IO,包括:
- 从当前level读取1MB
- 从level+1读取10~12MB(边界可能未对其)
- 将10~12MB的数据写入level+1
这意味着25次查找的成本与压缩1MB数据的成本相同。即,一次查找的成本与压缩40KB数据的成本大致相同。LevelDB在这方面有点保守,在触发压缩之前,每16KB数据允许大约一次搜索。而压缩后对于整个系统的性能来说是有提高的。
当allowed_seeks递减到小于0了,那么将标记为需要Compact的文件。但是由于Size Compaction的优先级高于Seek Compaction,所以在不存在Size Compaction的时候,且触发了Compaction,那么Seek Compaction才能执行。
计算sstable的allowed_seek都是在sstable刚开始新建的时候完成;而每次Get(key)操作都会更新allowed_seek,当allowed_seeks递减到小于0了,那么将标记为需要Compact的文件。1
2
3level = current_->file_to_compact_level_;
c = new Compaction(options_, level);
c->inputs_[0].push_back(current_->file_to_compact_);
Seek Compaction与Size Compaction不同点在于他不会有大量sstable要进行合并,每次只会有一个sstable参与。
合并 - DoCompactionWork
合并函数位于DBImpl::DoCompactionWork中。
首先是设置Compaction的快照。
如果没有快照,则删除所有的旧的重复数据;如果有快照,则只有sequenceNumber小于最老的快照的sequenceNumber的旧K/V数据可以删除。1
2
3
4
5if (snapshots_.empty()) {
compact->smallest_snapshot = versions_->LastSequence();
} else {
compact->smallest_snapshot = snapshots_.oldest()->sequence_number();
}
在这之后根据Compaction创建一个迭代器,该迭代器根据Compaction中的输入范围迭代其中的所有user key。这里的输入范围就是在创建的时候需要进行压缩的位于leveln的sstable文件列表。同时会按照key进行分组,每组相同key中的数据则按照sequence number进行排序。
对于level0来说,如果存在数据重叠,则重叠的数据整合为一个迭代器。如果不存在重叠或者不是level0的sstable,则为每个sstable创建一个迭代器并将所有迭代连接起来作为一个连接迭代器。1
Iterator* input = versions_->MakeInputIterator(compact->compaction);
创建迭代器所在的代码位于version_set.cc的VersionSet::MakeInputIterator(Compaction* c)函数。
然后就是循环遍历迭代器获取key并删除数据。首先解析key是否存在,如果存在则判断当前key是否是首次出现:1
if (!has_current_user_key || user_comparator()->Compare(ikey.user_key, Slice(current_user_key)) != 0)
由于相同的user key是连续顺序排列,在获取的某个user key之后它的数据必然有先后顺序,当获取到的user key已经出现过,并且它的sequence number小于已经出现过的user key,则表明这条数据已经被最新的数据所覆盖,则可以将其删除。
同时,对于当前的user key来说当一下条件成立后,这条数据就会被删除:
- 它不存在level+1级别的文件中
- 在level或者level-1级别的文件中有更大的sequenceNumber,表示文件存在新的记录,这条记录已过期
- 这条记录将在接下来的循环中被删除
后面是对文件的操作。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20if (compact->builder == nullptr) {
status = OpenCompactionOutputFile(compact);
if (!status.ok()) {
break;
}
}
if (compact->builder->NumEntries() == 0) {
compact->current_output()->smallest.DecodeFrom(key);
}
compact->current_output()->largest.DecodeFrom(key);
compact->builder->Add(key, input->value());
// Close output file if it is big enough
if (compact->builder->FileSize() >=
compact->compaction->MaxOutputFileSize()) {
status = FinishCompactionOutputFile(compact, input);
if (!status.ok()) {
break;
}
}
根据Compaction创建的梳理,合并文件并写入的过程是将数据与level+1的sstable进行合并的过程。