接上篇,上篇其实写的有些着急了,因此在按照方案修改的时候发现还有很多地方存在问题,除了一些显眼的代码复用修改外遇到的另外问题就是方法过长。下面通过一个读取日志函数的改进过程记录下自己对方法优化的方式。
正文
废话不多说,先上原代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61/**
* 读取日志
* 其中:
* bucket.add:将路由节点加入路由表中
*/
private void readLog1(String logPath) {
File file = new File(logPath);
if (!file.exists()) {
return;
}
var findEd = new HashSet<String>();
var list = new ArrayList<LayoutLog>();
try (var raf = new RandomAccessFile(file, "r")) {
if (raf.length() == 0) {
return;
}
long start = raf.getFilePointer();
long nextEnd = start + raf.length() - 1;
String result;
raf.seek(nextEnd);
int c = -1;
while (nextEnd >= start) {
c = raf.read();
if (c == '\r' || c == '\n') {
result = raf.readLine();
LayoutLog layoutLog = LogParser.parser.parseLayout(result);
if (Objects.nonNull(layoutLog)) {
if (bucket.contains(layoutLog.getNodeId())
|| findEd.contains(layoutLog.getNodeId())) {
break;
}
findEd.add(layoutLog.getNodeId());
list.add(layoutLog);
}
nextEnd -= 1;
}
nextEnd -= 1;
if (nextEnd >= 0) {
raf.seek(nextEnd);
if (nextEnd == 0) {
LayoutLog layoutLog = LogParser.parser.parseLayout(raf.readLine());
if (Objects.nonNull(layoutLog)) {
if (bucket.contains(layoutLog.getNodeId())
|| findEd.contains(layoutLog.getNodeId())) {
break;
}
findEd.add(layoutLog.getNodeId());
list.add(layoutLog);
}
}
}
}
} catch (IOException e) {
Logger.systemLog.error(LogFormat.SYSTEM_ERROR_FORMAT, "读取路由节点操作日志文件失败", e.getMessage());
}
list.forEach(node -> bucket.add(node.toNode()));
}
这个函数的作用在于从下往上按行读取日志记录并解析,然后将解析后的路由节点信息加入路由表中。
存在的问题如下;
- 这个函数位于
RouterLayout类中,这个类不应该有直接对文件操作的动作。 - 函数过长且可读性差,这个函数我在一周前写的,但现在需要一行一行重新阅读才能了解具体是如何操作的
我对此的主要分析过程如下:
首先,确定该函数具体需要执行哪些操作,将其绘制成流程图如下: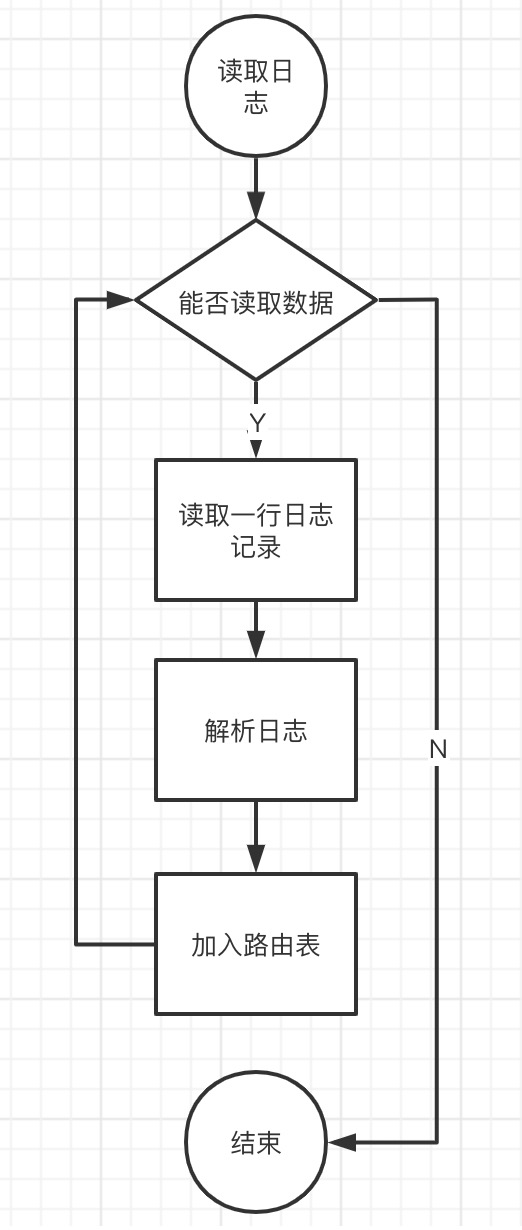
这样我知道了这个函数主要进行的操作,然后根据OOP理论将各个操作将其划分到对应的对象中:
- 主流程肯定位于
Routerlayout对象中 - 读取文件的过程应该要有一个专门的
日志读取器 - 日志的解析也是一样,要有一个专门的
日志解析器将其从字符串转换为对象
同时观察其中的if判断逻辑,我第一时间想到的是通过迭代器进行日志文件的逐行获取,这个想法没问题!因此获得的日志读取器对象如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79/**
* 日志阅读器
* 从日志的最后一行逐行往上读取日志
*/
public class LogReader implements Iterator<String>, Closeable {
private final boolean exist;
private final RandomAccessFile raf;
private final long start;
private long nextEnd;
private String returnLine;
public static LogReader create(String logPath) throws IOException {
var file = new File(logPath);
return new LogReader(logPath, file.exists());
}
private LogReader(String logPath, boolean exist) throws IOException {
this.exist = exist;
this.raf = new RandomAccessFile(logPath, "r");
this.start = raf.getFilePointer();
this.nextEnd = start + raf.length() - 1;
this.returnLine = null;
if (nextEnd >= 0) {
raf.seek(nextEnd);
}
}
public boolean hasNext() {
if (!exist || nextEnd < start) {
return false;
}
try {
if (raf.length() == 0) {
return false;
}
int c = -1;
while (nextEnd >= start) {
c = raf.read();
if (c == '\r' || c == '\n') {
returnLine = raf.readLine();
//越过换行符
nextEnd -= 1;
if (Objects.nonNull(returnLine))
break;
}
//往上读取
nextEnd -= 1;
if (nextEnd >= 0) {
raf.seek(nextEnd);
if (nextEnd == 0) {
returnLine = raf.readLine();
}
}
}
} catch (IOException e) {
Logger.systemLog.error(LogFormat.SYSTEM_ERROR_FORMAT, "读取日志文件失败", e.getMessage());
}
return Objects.nonNull(returnLine);
}
public String next() {
var result = returnLine;
returnLine = null;
return result;
}
public void close() throws IOException {
raf.close();
}
}
实现Closeable接口的原因是需要关闭文件的读取对象流。
在使用的时候可以直接通过使用一般的迭代器一样使用日志读取器:1
2
3
4var reader = FileReader.create(logPath);
while (reader.hasNext()) {
var logLine = reader.next();
}
由于原来就有日志的读取器,因此只需要针对解析流程做一个简化即可,最终读取日志的函数修改如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23/*
读取本地日志,将日志中的节点重新加入到路由表中
LOG_FILE = logPath
*/
private void readLog() {
var logFile = new File(LOG_FILE);
if (!logFile.exists()) {
return;
}
try (var reader = LogReader.create(LOG_FILE)) {
while (reader.hasNext()) {
String logLine = reader.next();
var layout = LogParser.parser.parseLayout(logLine);
if (Objects.isNull(layout))
continue;
if (bucket.contains(layout.getNodeId()))
break;
bucket.add(layout.toNode());
}
} catch (IOException e) {
Logger.systemLog.error(LogFormat.SYSTEM_ERROR_FORMAT, "读取日志出错", e.getMessage());
}
}
瞬间清新了很多!
总结
在对函数进行瘦身的时候,首先需要划分出函数要执行的各个操作,并将各个操作按照类型进行分区,这里的分区到最后就是将其封装为各个对象。