构建网络拓扑
Epidemic采用Kademlia协议来构建网路拓扑,通过在配置文件中设置的随机字符串(可选)生成一个160位的二进制数作为网络节点的Id。
两个节点之间的距离通过他们各自的id进行异或(XOR)计算,定义两个节点之间的距离为两个id之间前缀相同的位数。
Dis(M, N) = XOR(M, N)
由此可以知道节点之间距离越近其公共前缀越长。
这里的距离表示的是Id之间的距离,并不是节点之间实际的网络距离。
基于此,我们可以构建出一棵前缀树用于记录并管理所有的节点信息: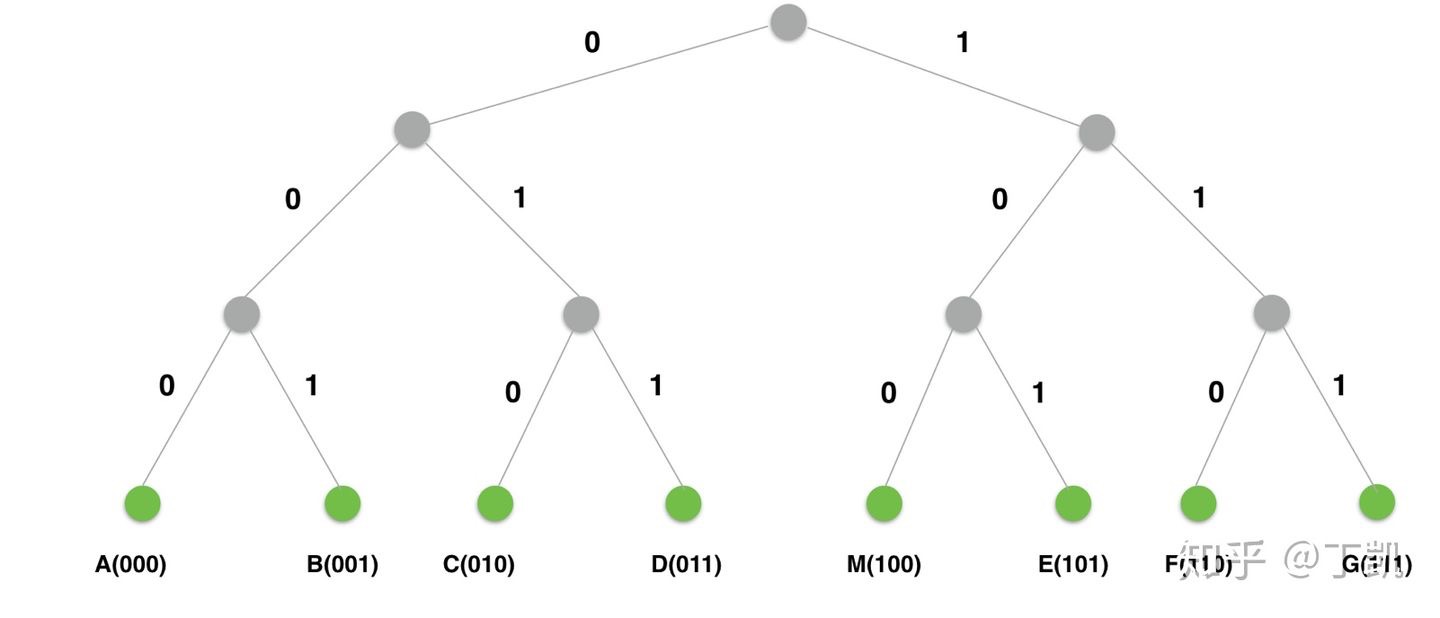
与这个相关的文章链接在这里
节点路由
由Kademlia协议可以得知,任意两个节点之间的距离的范围为[0, 160]。当距离为160的时候两个节点相同,因此对于一个存储节点来说,可以维护一个长度为160的bucket数组,数组的下标就是其他节点与自身节点的距离,bucket本身则是一个固定长度的集合用于保存网络节点,其中的网络节点满足他们与本地节点的距离大于等于所在下标。
从id的生成策略可知一共可以生成2^160个不同的id,如果要让一个存储节点维护所有的id显然是非常不现实的。因此节点有一个配置参数(BucketKey)用于表示每个Bucket维护多少个节点,每当超过这个数值之后会将新的节点加入一个有界队列的缓存中。
缓存是一个实现了LRU的有界队列,它的大小也是BucketKey,当超过这个数值后会将队列末尾的节点丢弃。
Bucket分裂:
在具体的实现中一开始只有1个Bucket,它的下标为0表示其中维护的所有节点与本地节点的距离大于等于0。当集合中节点数量超过大小最大后进行Bucket分裂,分裂的实现为创建一个新的Bucket并将原本Bucket中的所有与本地节点距离大于0的节点放入新的集合中。在分裂之后的2个Bucket中,下标为0的Bucket集合中所有节点与本地节点的距离都为0,下标为1的Bucket集合中的所有节点与本地节点的距离都大于等于1.
路由算法:
该算法的核心在于如何只根据目标id在集群中找到它的地址或者与该id最接近的目标节点地址。
在一个对等网络中,某节点要查询其他节点的信息时,它能依赖的信息有两个:
1. 目标节点id
2. 当前节点所维护的路由表
由于每个节点不能维护一张涵盖所有节点的路由表,因此对于寻找目标节点的核心思想是:逐步迭代、递进查找。
节点变更
节点上线:
当一个新节点上线后需要给它一个一存在的节点地址作为接入对等网络的“联系人”。当新节点启动后通过“联系人”调用查询节点函数,查询的目标节点是它自身的节点,“联系人”返回距离新节点最近的节点列表后重复查询操作,直到新节点的Bucket数量超过2或者某次返回的节点已经全部位于Bucket中为止。
收到查询操作的“联系人”节点也能得知有新节点上线,并将这个新节点加入自身的路由表管理。
节点离线:
节点离线并不会触发特殊操作。对于其他节点来说,有一个定时任务每经过一定时间就执行ping操作用于检查Bucket中无法通信的节点,如果某个节点无法通信它会被从bucket集合中被删除,并从节点缓存队列中查询是否有与当前节点距离相同的缓存节点,如果存在则从缓存中取出并加入bucket中。
对象存储
在对等网络中实现对象存储需要面对两个问题:
1. 如何建立对象与网络节点之间的映射
2. 如何保证节点动态变化时保证对象的可访问
对象与节点的映射:
节点与对象的映射有一种办法就是建立一张节点与对象之间的映射表,但是这样这个映射表将会变得庞大并成为系统瓶颈,违背了对等网络的原则。
第二种方法就是通过算法计算文件的特征码,并且这个特征码的长度为160位与节点ID对应,将文件存入与它的特征码最接近的节点中。
这个特征码还能作为文件的完整性校验码。
对象Re-Publishing:
在节点的动态变化下,会产生一下两个问题:
- 对象<key, value>被存储在与key距离最接近的K个节点,如果K个节点全部离线,那么对象便不可达;
- 对象<key, value>被存储在与key距离最接近的K个节点,如果集群新加入一个节点N,对象距离N更近,需要对象迁移到N。
针对上诉情况的一个解决方案是:当一个新节点加入并被其他节点感知到后,如果节点检测到自身所保存的某些文件距离新节点更近,则将该文件推送到新节点。这个操作叫做Re-Publishing。感知过程通常是新节点加入后通过“联系人”从集群中获取节点丰富自己路由表的时候。
由于集群网络中节点每时每刻都在改变,如果每次新节点加入都进行一次数据拷贝,则集群中大量的流量都会被用来进行文件复制而不是提供客户端使用。
我们可以通过定时执行这个操作来减少对网络中流量的占用。在Kademlia作者的论文中推荐的时间为1小时,每经过1小时对网络中的每个对象执行一次Re-Publishing。每一次Re-Publishing包括两个步骤:
- 查询当前最近的K个节点信息
- 节点向上一步获得的节点发送数据存储消息,从而完成数据更新
这样做会导致短时间内网络流量激增,通过对上诉行为的分析可以知道有很多操作其实是不需要的。
- 如果1小时内网络拓扑并没有变化则不需要进行Re-Publishing
- 对于K个节点,其中如果已存在要Re-Publishing的对象,则不需要进行Re-Publishing
- 新节点加入的时候与他相临的其他节点都可以收到通知,并不需要重新进行一轮查询