这是一篇在阅读《大规模分布式存储系统:原理解析与架构实战》时的阅读笔记,由于长时间碎片阅读的关系导致在做这种读书笔记的时候接近复制粘贴。虽然其中会有一小部分自己的想法但都十分零碎,希望后续能改进。
Google spanner是谷歌的全球级分布式数据库。Spanner的扩展性达到了全球级,可以扩展到数百个数据中心,数百万台机器,上万亿行记录。除了夸张的可扩展性之外,他还能通过同步复制和多版本控制来满足外部一致性,支持跨数据中心事务。
Google Spanner的成功表示分布式技术能够给用户呈现关系数据库的数据模型.
数据模型:
Spanner的数据模型与Megastore系统比较类似。
如图所示,对于一个典型的相册应用,需要存储其用户和相册,可以用上面的两个SQL语句来创建表。
Spanner的表是层次化的,最底层的表是目录表(Directory table),其他表创建时,可以用INTERLEAVE IN PARENT来表示层次关系。
图中所示,Users是Directory的上层,Albums是Users的上层
Spanner中的目录相当于Megastore中的实体组,一个用户的信息(user_id, email)以及这个用户下的所有相片构成一个目录。
实际存储时,Spanner会将同一个目录的数据存放到一起,只要目录不太大,同一个目录的每个副本都会分配到同一台机器。因此,针对同一个目录的读写事务大部分情况下都不会涉及跨机操作。
架构:
Spanner与Bigtable、Megastore不同,它是构建在新的分布式文件系统Colossus之上。相比GFS,Colossus主要改进点在于实时性,并且支持海量小文件。
GFS、Bigtable、Megastore之间的不同:
- GFS:构建了分布式存储的底层数据、文件存储。
- Bigtable:在基础的数据存储基础上抽象了“表格”的概念,对数据进行一个初步的分类汇总
- Megastore:在Bigtable的基础上,即在“表格”的基础上更近一层提供了“对象组”概念,将表格抽象为现实事务中能够存在的对象。
由于Spanner是全球性的,因此它有两个其他分布式存储系统没有的概念:
- Universe:一个Spanner部署实例称为一个Ubiverse。目前全球有3个,一个开发、一个测试、一个线上。Universe支持多数据中心部署,且多个业务可以共享同一个Universe。
- Zones:每个Zone属于一个数据中心,而一个数据中心可能有多个Zone。一般来说,Zone内部的网络通信代价较低,而Zone与Zone之间通信代价很高。
前面说过,谷歌的服务器网络与传统的三层式网络不同,它是扁平化拓扑结构,即三级CLOS网络,同一个集群内最多支持20480台服务器。也就是说一个Zone就是一个三级CLOS网络集群。
- Universe Master:监控这个Universe里Zone级别的状态信息
- Placement Deiver:提供跨Zone数据迁移功能
- Location Proxy:提供获取数据的位置信息服务。客户端需要通过它才能够知道数据由哪台Spanserver服务
- Spanserver:提供存储服务,功能相当于Bigtable的Tablet Server。
每个Spanserver会服务多个子表,而每个子表又包含多个目录。客户端往Spanner发送读写请求时,首先查找目录所在的Spanserver,接着从Spanserver读写数据。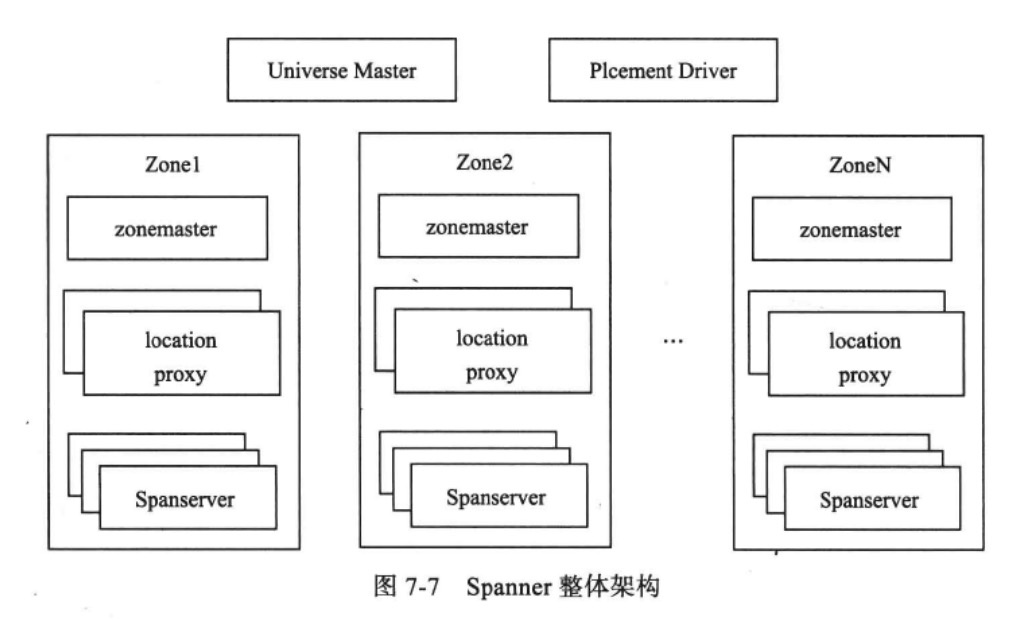
Q:如何存储目录与Spanserver之间的映射关系?
A:假设每个用户对应一个目录,全球共有50亿用户,这在单台机器上是无法保存的,这里谷歌没有说明如何做到,但猜测是将映射关系这样的元数据当成元数据表格,和普通用户表格采取相同存储的方式。
把映射关系存入表格中,这样就从“如何存储目录与Spannserver之间的映射关系”这个问题转变为“如何在分布式表格系统中存入大量数据”。而针对问题2,Bigtable中有成熟清晰的做法。将用户id划分为多个范围分别存储,并维护用户id范围与表格之间的映射。
复制与一致性:
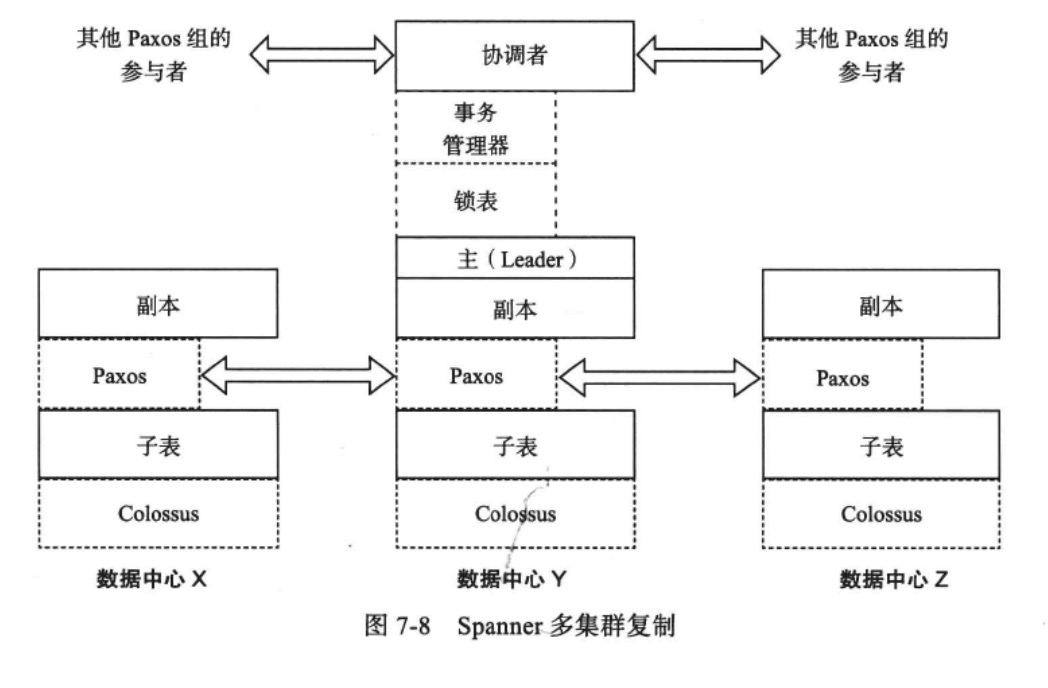
如图所示,每个数据中心运行着一套Colossus,每个机器有100~1000个子表,每个子表会在多个数据中心部署多个副本。为了同步操作系统中的操作日志,每个子表上会运行一个Paxos状态机。
Paxos协议会选出一个副本作为主副本,这个主副本的寿命默认是10秒。
正常情况下,主副本快要到期的时候会主动将其再次选为主副本,如果出现异常,在10秒过后其他副本会开启一轮新的选举。
通过Paxos协议,实现了跨数据中心的多个副本之间的一致性。
每个主副本所在的spanserver还会实现一个锁表用于并发控制,读写事务操作某个子表上的目录时需要通过锁表避免多个事务之间互相干扰。
除了锁表,每个主副本上还有一个事务管理器。如果事务在一个Paxos组里面,可以绕过事务管理器。然是一旦事务跨多个Paxos组,就需要事务管理器来协调。
锁表实现单个Paxos组内的单机事务,事务管理器实现跨多个Paxos组的分布式事务。为了实现分布式事务,采用的是两阶段提交协议,此时有一个Paxos组的主副本为协调者,其他Paxos组的主副本为参与者。
TrueTime:
为了实现并发控制,数据库需要给每一个事务分配一个全局唯一的事务id。
但是在分布式系统中很难做到全局唯一,常用的办法就是采用单台服务器用于专门生成全局唯一id的作用。例如Google Percolator(Google Caffeine的底层存储系统呢)中的做法的,专门部署一套Oracle数据库用于生成全局唯一id。虽然Oracle逻辑上是个单点,但是他功能单一,因而能够高效完成任务。
Spanner选择了另一种做法:全球时钟同步机制TrueTime。
TrueTime是一个提供本地时间的接口,但与Linux上的gettimeofday接口不一样的是:它出了返回一个时间戳t,还会给出一个误差e。例如:返回的时间戳是20:23:30:100,而误差是5ms,那么真实的时间在20:23:30:95~106之间。真实的系统e平均下来只有4毫秒。
TrueTimeAPI实现的基础是GPS和原子钟。之所以要用两种技术来处理,是因为原子钟很稳定,当GPS失灵的时候,原子钟仍然能够保证在相当长的时间内,不会出现偏差。
原子钟就是通过几个校准时间的域名获取准确的时间。这跟前面那个假设一台单点的全局唯一id服务器好像。只不过把这个工作交给了专业机构。
每个数据中心都需要部署一些主时钟服务器(Master),其他机器上部署一个从时钟进程(Slave)来从主时钟服务器同步时钟信息。有的主时钟用GPS,有的主时钟服务器用原子钟。
Slave在同步的时候根据多数派读的规则进行,通过对比多台主时钟服务器返回的结果来确定本地的时钟。
采用时钟的好处:主时钟服务器不会有数据积存,对硬盘的依赖程度低,性能高。因为处理每个请求都在内存中完成,不需要有IO的读写操作。
并发控制:
Spanner使用TrueTime来控制并发,实现外部一致性,支持一下几种事务:
- 读写事务
- 只读事务
- 快照读,客户端提供时间戳
- 快照读,客户端提供时间范围
不考虑TrueTime
即不考虑TrueTime的误差,假设TrueTimeAPI返回的时间都是精准的。如果事务读写的数据只属于同一个Paxos组,那么,
每个读写事务的执行步骤如下:
a. 获取系统当前时间戳
b. 执行读写操作,并将第1步取得的时间戳作为事务的提交版本
每个只读事务的执行步骤如下:
a. 获取系统当前时间戳,作为读事务的版本
b. 执行读取操作,返回客户端所有提交版本小于读事务版本的事务操作结果
读写事务需要对数据进行修改,因此需要在事务内部对数据进行读写。如果是读取操作,则返回的数据也是当前事务读取出来的结果
只读事务不涉及写操作,因此只需要返回最后一个成功的事务的数据状态即可,因为它自身不会对数据进行修改,所以不需要让只读事务本身再去重新对数据进行扫描读取。
快照读和只读事务的区别在于:快照读将指定读取事务的版本,而不是取系统当前时间戳。
如果事务读别的数据涉及多个Paxos组,那么事务就扩大为分布式事务,需要使用两阶段提交协议。执行步骤如下:
- Prepare:客户端将数据发往多个Paxos组的主副本,同时,协调者主副本发起prepare协议,请求其他的参与者主副本锁住需要操作的数据。
- Commit:协调者主副本发起Commit协议,要求每个参与者主副本执行提交操作并解除prepare阶段锁定的数据。协调者主副本可以将它的当前时间戳作为该事务的提交版本,并发送给每个参与者主副本。
只读事务读取每个Paxos组中提交版本小于读事务版本的事务操作结果。
只读事务需要保证不会读取到不完整的数据,也就是说,不会读取到尚未提交的事务。
例如:只读事务读取到了两个Paxos组的事务A和B,其中A已经提交,但是B尚未提交还处于prepare阶段。只读事务会等待B协调者发起commit请求后再读取。
考虑TrueTime
问题在于,只要事务T1的提交操作早于事务T2的开始操作,即使考虑TrueTimeAPI的误差因素(-e到+e之间,e的平均值为4ms),Spanner也能保证事务T1的提交版本小于事务T2的提交版本。
Spanner使用了一种被称为延迟提交(Commit Wait)的手段,即如果事务T1的提交版本为时间戳tcommit,那么,事务T1会在tcommit+e之后才能提交。如果事务T2开始的绝对时间为tabs。那么,事务T2的提交版本至少为tabs+e。这样,就保证了事务T1和T2之间严格的顺序,这也意味着每个写事务的延时至少为2e。
这里是考虑不同机器之间TrueTime的误差,由于TrueTimeAPI在调用的时候会产生误差e,因此为了确保不同服务器上的事务执行顺序的准确性,需要在执行过程中将误差给计算进去。这里主要的想法就是宁愿事务提交的晚也不要过早提交导致顺序错误。通过在事务完成后再延时2e的时间将这个误差给算进事务,使得其他服务器虽然事务执行需要在其后,但是读取的TrueTime在其前的情况下也能保证最终事务执行的顺序。
例子:有两个事务T1、T2.执行顺序是T1-T2.两者同时从TrueTimeAPI中获取时间戳:t1、t2.由于会有误差,假设t2 < t1,如果按照这个时间戳来计算,T2的提交顺序将会在T1之前,T2的提交需要往后延时2e时间,保证在误差范围内T1优先执行。
Spanner实现功能完备的全球数据库付出了一定代价。
数据迁移:
目录是Spanner中对数据分区、复制和迁移的基本单位,用户可以指定一个目录有多少副本,分别存放在哪些机房中,例如将用户的目录存放在这个用户所在地区附近的几个机房中。
一个Paxos组包含多个目录,目录可以在Paxos组之间移动。Spanner移动一个目录一般处于以下几种考虑:
- 某个Paxos组的负载太大,需要切分;
- 将数据移动到离用户更近的地方,减少访问延时
- 把经常一起访问的目录放进同一个Paxos组
移动一个50MB的目录大约需要几秒钟时间。实现时,首先将目录的实际数据移动到指定位置,然后再用一个院子操作更新元数据没从而完成整个移动过程。
这个过程如果中途出现意外,那么需要保证原有元数据依旧能够提供访问,所以数据的移动首先是将数据复制一份,而不是“剪切”。
讨论:
谷歌的分布式存储系统从Bigtable-Megastore-Spanner。底层通过分布式技术实现可扩展性,上层通过关系数据库的模型和接口将系统的功能暴露给用户。
体现了分布式技术与传统数据库技术融合的必然性。