这是一篇在阅读《大规模分布式存储系统:原理解析与架构实战》时的阅读笔记,由于长时间碎片阅读的关系导致在做这种读书笔记的时候接近复制粘贴。虽然其中会有一小部分自己的想法但都十分零碎,希望后续能改进。
对于关系型数据库,有很多思路可以实现关系数据库的可扩展性。例如:
- 在应用层划分数据,将不同的数据分片划分到不同的关系数据库上,如Mysql Sharding;
- 或者在关系数据库内部支持数据自动分片,如Microsoft SQL Azure;
- 或者干脆从存储引擎开始重写一个全新的分布式数据库,如Google Spanner以及Alibaba OceanBase。
数据库中间层:
为了扩展关系数据库,最简单也是最常见的做法就是应用层按照规则将数据拆分为多个分片,分不到多个数据库节点,并引入一个中间层来对应用屏蔽后端的数据库拆分细节。类似于这样: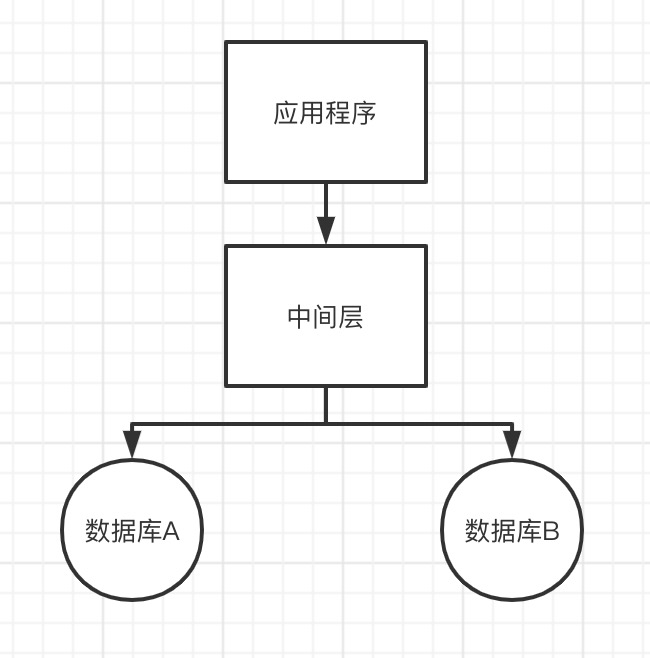
架构:
以MysqlSharding架构为例,分成几个部分:中间层dbproxy集群、数据库组、元数据服务器、常驻进程。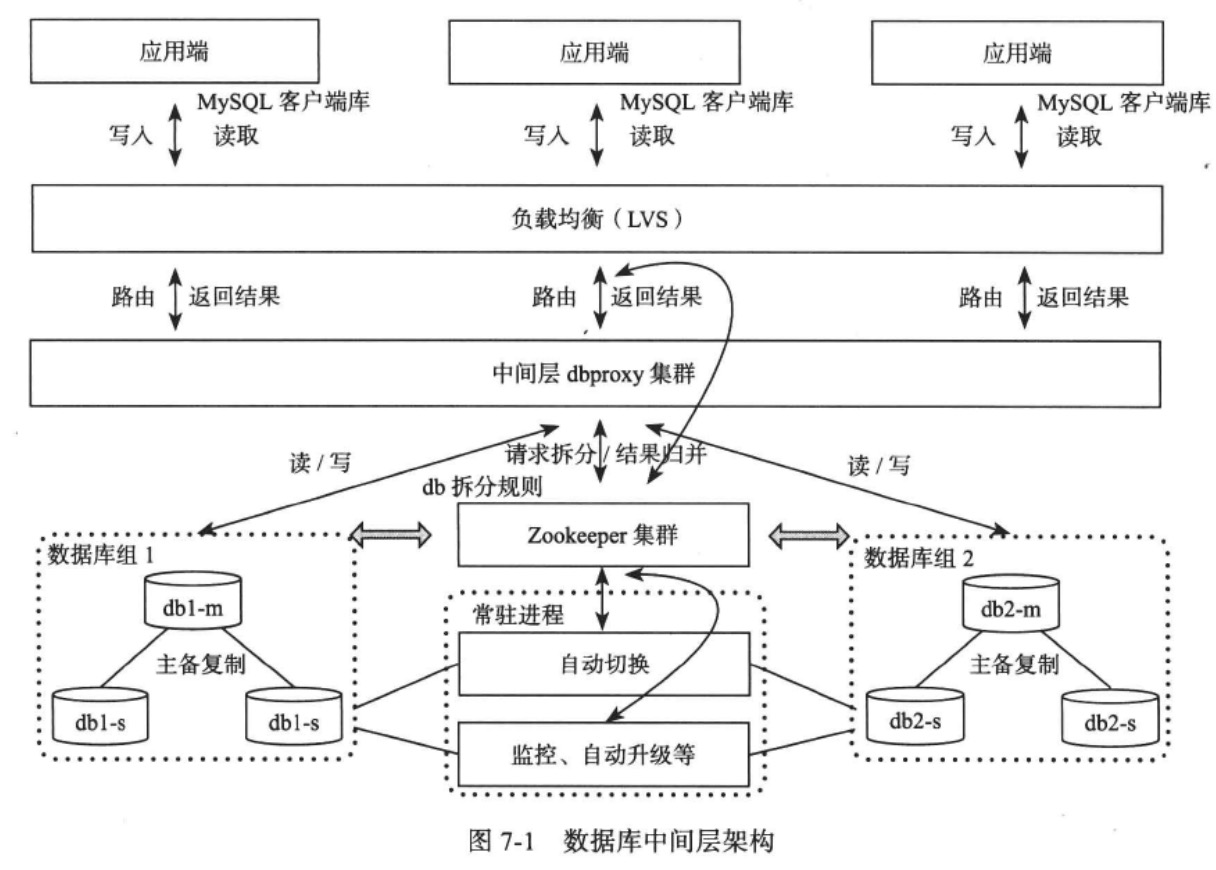
Mysql客户端库:
应用程序通过Mysql原生的客户端与系统交互,支持JDBC,原有的单机访问数据库程序可以无缝迁移。
中间层dbproxy:
解析客户端SQL请求并转发到后端的数据库。在这一步它负责解析Mysql协议,执行SQL路由,SQL过滤,读写分离,结果归并,排序以及分组,等等。
中间层由多个无状态的dbproxy进程组成,不存在单点问题。
中间层通过LVS进行负载均衡,但由于部署负载均衡服务需要多经历一层网络开销,因此常见的做法是将LVS放置在Mysql客户端上,由客户端处理请求负载均衡以及中间层服务器故障等情况。
数据库组dpgroup:
每个dbgroup由N台数据库机器组成,其中一台为主机(Master),另外N-1台为备用(Slave)。
主机提供服务,包括写事务与强一致读服务,并将操作以binlog的形式同步到备机器上,备机器可以支持有一定延迟的读事务。
备机器上的数据从主机同步需要一个时间段,因此哪些刚写入的数据可能无法在备机器上读取到,但是可以提供已经经过一段时候后的数据的读取服务。
元数据服务器:
元数据服务器主要负责维护dbgroup拆分规则并用于dbgroup选主。
dbproxy通过元数据服务器获取拆分规则从而确定SQL语句的执行计划。
如果dbgroup的主机出现故障,需要通过元数据服务器选主。元数据服务器本身也需要多个副本实现HA,一种常见的方式是采用Zookeeper实现。
zookeeper本身能够存储信息,同时自身也是一个高效的分布式锁服务,通过互斥锁能够实现选主的功能
常驻进程agents:
部署在每台服务器上的常驻进程,用于实现监控,单点切换,安装,卸载程序等。
dbgroup中的数据库需要进行主备切换,软件升级等,这些控制逻辑需要与数据库读写事务处理逻辑隔离开来。
这些逻辑跟业务毫无关系,因此不能让这些逻辑阻塞事务的执行。
如果数据库按照用户哈希分区,同一个用户的数据分布在同一个dbgroup上,这样容易出现“数据倾斜”问题。如果SQL请求只涉及同一个用户,那么中间层将请求转发给相应的dbgroup,等待返回结果并返回给客户端;
如果SQL请求涉及多个用户,那么中间层需要转发给多个dbgroup,等待返回并将结构执行合并、分组、排序等操作后返回客户端。
扩容:
Mysql Sharding集群一般按照用户id进行哈希分区,这里存在两个问题:
- 集群容量不够怎么办
- 单个用户的数据量太大怎么办(数据倾斜)
问题1:
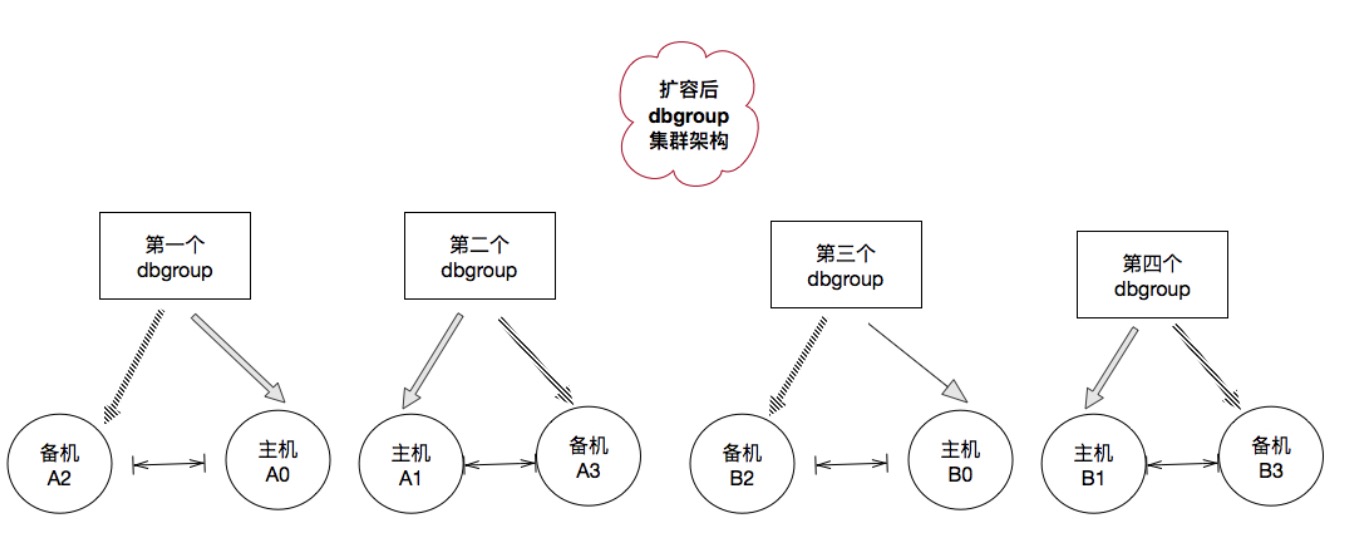
Mysql Sharding集群会采用双倍扩容的方案,即从2台服务器扩到4台,接着再扩容到8台。
假设原来有2个dbgroup,第一个dbgroup的主机为A0,备机为A1,第二个dbgroup的主机为B0,备机为B1.按照用户id哈希取模,结果为奇数的用户分布在第一个dbgroup,结果为偶数的用户分布在第二个dbgroup。常见的一种扩容方式如下:
- 等待A0和B0的数据同步到其备服务器。
- 停止写服务,等待主备完全同步后解除A0与A1、B0与B1之间的主备关系
- 修改中间层的映射规则,将哈希值模4等于1的用户数据映射到A1,哈希值模4等于3的用户数据映射到B1
- 开启写服务,用户id哈希值模4等于0、1、2、3的数据分别写入到A0、A1、B0、B1.相当于有一半的数据分别从A0、B0迁移到A1、B1.
- 分别给A0、A1、B0、B1增加一台备机
- 最终,集群由2个dbgroup扩容到4个dbgroup。
这种方案扩容后,A1、B1上的数据依旧有一部分属于A0、B0上,这部分并没有随着通过用户取模重新划分后删除,而是依旧保留,这种情况下这些数据属于垃圾数据,因为不可能再有响应的用户请求到这些节点上,也不会有主节点将数据同步过去,因此扩容后需要有一个负载均衡方案或者垃圾回收方案用于将这些数据删除。
例如,A0的有主键范围为(0, 100]的用户数据,B0有用户主键范围是(100, 200]的数据,扩容后A0、A1、B0、B1的主键范围分别为(0, 50]、(50, 100]、(100, 150]、(150, 200];但是他们拥有的数据的主键范围是(0, 100]、(0, 100]、(100, 200]、(100, 200]
分库分表:常用的方案是range+hash的模式,首先通过判断数据主键的范围来确定数据属于哪个数据库组,然后主键和数据库组中的数据库数量取模最终确定数据存在哪里,扩容只需要新增一个范围内的数据库组即可。但是这样只适用于单表记录,如果是用户的话,一个用户的数据量会越来越大,最终达到单机的极限。
问题2:
可以在应用层定期统计大用户,并且将这些用户的数据按照数据量拆分到多个dbgroup。
讨论:
引入数据库中间层将后端分库分表对应用透明化再大型互联网公司内部很常见。这种做法简单但是会有一些问题:
- 数据库复制:Mysql主备之间只支持异步复制,而且主库压力较大时可能产生很大的延迟,因此主备切换可能会丢失最后一部分更新事务,这时需要人工介入
- 扩容问题:这个过程涉及到数据的重新划分,就像上面记录的,每次扩容都会在dbproxy上增加一层路由,容易出错。
- 动态数据迁移问题:如果某个数据库组压力过大,需要将其中部分数据迁移出去,迁移过程需要总控节点整体协调,以及数据库节点的配合,这个过程很难做到自动化。