配合此文食用。也是一种读后感吧,既然学习分布式存储了,raft早晚都是要接触的。
在分布式系统中,如果不是昂贵的设备的话,一般硬件的服务器集群中,节点会时常异常下线。因此大部分的分布式存储系统都要求支持节点动态增删,并在此基础上保证系统服务的稳定性以及数据的一致性。
成员变更是在集群运行过程中改变运行一致性协议的节点,如增加、减少节点、节点替换等。成员变更过程不能影响系统的可用性。
成员变更过程中对常用的一致性算法,比如paxos、raft会产生一定的影响, 他们加入集群后会扩大集群的多数派集合,但是此时他们的状态与原先节点还没有保持一致,当新加入或者产生变更的节点数量大于等于原有节点数量的时候,就会对集群一致性算法产生影响。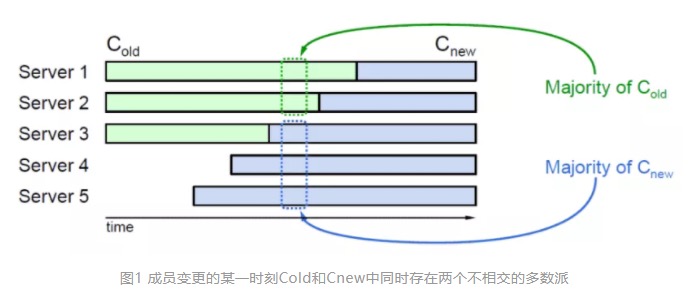
问题如下:当处于画框的时间点并触发选举后,节点1和节点2还是旧的配置文件,因此他们会从节点1~节点3中选出Leader;而节点3~节点5已经是新的配置文件了,他们会从节点3~节点5中选出新的Leader。此时就会出现两个Leader,即脑裂。
raft提出了两阶段的成员变更方法:Joint Consensus。
成员变更
Joint Consensus(联合共识模式)成员变更
新成员配置:Cnew
旧成员配置:Cold
当Leader需要进行成员变更的时候,首先往所有的Follower发送联合共识日志(Cnew,Cold),所有follower收到后即可生效,不需要等待Leader发送commit命令。
在配置变更的过程中,保留Cold,由于分布式系统中每次元数据变更都会记录对应的版本ID,因此可以很方便的对Cnew与Cold进行区分。
Leader在这期间提交的日志会有两种情况,一种属于原有日志提交,这种时候需要Cnew与Cold两个配置都确认后才能提交;另一种就是只提交Cnew,在这之后系统全部切换为Cnew,所有提案不再经过Cold,而且这一步也是直接生效不需要Leader提交commit。
当Leader宕机的时候,集群中选举出来的新Leader根据自身配置的情况来选择哪种成员变更方式。这里有个问题,在成员变更途中Leader下线后如何选举出全局唯一的Leader?此时集群中的节点会有两种状态Cold,(Cnew,Cold),而为了保证不会出现脑裂现象,当节点中的配置为(Cnew,Cold)时,采用的是Cold配置。
主要的问题:Cnew与Cold节点任意多数派不相交,导致选举出两个Leader。如果存在相交,那么Cnew与Cold节点就无法各自形成多数派。
单步成员变更
造成上诉问题的原因在于同时对所有节点进行变更配置的时候由于网络先后等因素导致一部分节点配置已变更,另一部分没有变更。
既然如此只要保证每次变更一定抵达,并且在一次变更完成之后再发送下一个变更请求就可以避免新旧配置多数派存在交集。即,每次成员变更只允许增加或删除单个成员。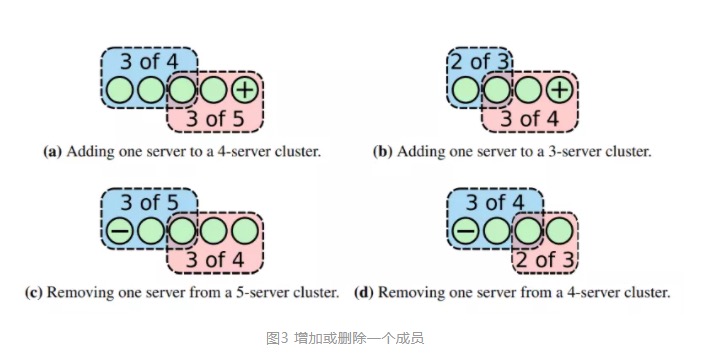
上图中,颜色不同的框表示应用了不同成员配置的节点,可以看到,每次变更一个成员后,两种配置成员中必定会有一个交集。
如果集群中有大量的成员需要变更,那这个时间就十分漫长。
Raft单步成员变更的问题
Raft单步成员变更的正确性问题
这个问题在于上一个Leader没有同步之后重新上线同步日志,会导致这期间选出来的新Leader的相关日志被抹除,但是如果采用操作追加的话不就没有这个问题了吗?Leader上线后如果检测到变更没有同步到其他节点,那么将变更的操作追加到其他节点的操作日志上,由其他节点进行恢复,如果恢复过程中发现Follower的同步日志与Leader的同步日志不一致,就将其同步回Leader。
这里还有个原因就是集群中Leader下线后如果重新上线,那他的身份还是属于Leader,可以继续执行下线前的操作。
raft的解决办法是新Leader在同步成员变量前要往集群中发送一条no-op日志,用于发现上一任Leader未提交的成员变更日志。这步操纵属于多数派写,则根据单步成员变更原则,必然能够与上一任Leader未提交的成员变更日志至少有一个交集,有了这个标记后,当上一任Leader重新上线并尝试同步日志的时候会发现他所属的节点中存在no-op记录,则使得新上线的Leader凭证失效,重新成为普通节点。
Raft单步成员变更的可用性问题
在进行单步成员变更的时候,如果集群中某个节点出现问题需要被新的节点替换,那“删除旧的节点”与“添加新的节点”也会是独立成两个操作。
如果出现二分网络分区的情况,由于两个节点位于同一机房,另外两个节点和他们不在同一个网络拓扑结构上,会导致位于同一机房的两个节点与另外的两个节点状态不一致,此时跟上述问题一样,两种状态的节点集合他们的多数派有可能不相交导致脑裂问题。
这种情况是由于新旧节点同时存在集群中导致的,因此在进行单步成员变更的时候先删除旧节点再添加新节点即可,原因就是新旧两种类型的多数派一定会有相交。
另一种方法就是采用Joint Consensus,使得集群中存在中间状态,也能保证不会出现脑裂问题。
Raft成员变更的工程实践
在工程上多数采用Joint Consensue,可能是因为采用另一种方法,如果删除了旧节点但是新节点加入失败的时候会造成数据丢失?
至于后面的工程实践,我没工程经验只能看看了눈_눈