这是一篇在阅读《大规模分布式存储系统:原理解析与架构实战》时的阅读笔记,由于长时间碎片阅读的关系导致在做这种读书笔记的时候接近复制粘贴。虽然其中会有一小部分自己的想法但都十分零碎,希望后续能改进。
TFS = Taobao File System
FH = Facebook Haystack
Blob文件系统的特点是数据写入后基本都是只读,很少出现更新操作。
Taobao File System
TFS架构设计时需要考虑如下两个问题:
因此TFS的设计思路是:多个逻辑图片共享一个物理文件
系统架构
TFS于GFS的不同点:
- TFS内部不维护文件目录树,每个小文件使用一个64位的编号表示;
- TFS是一个读多写少的应用,相比GFS,他的写流程可以做的更加简单高效
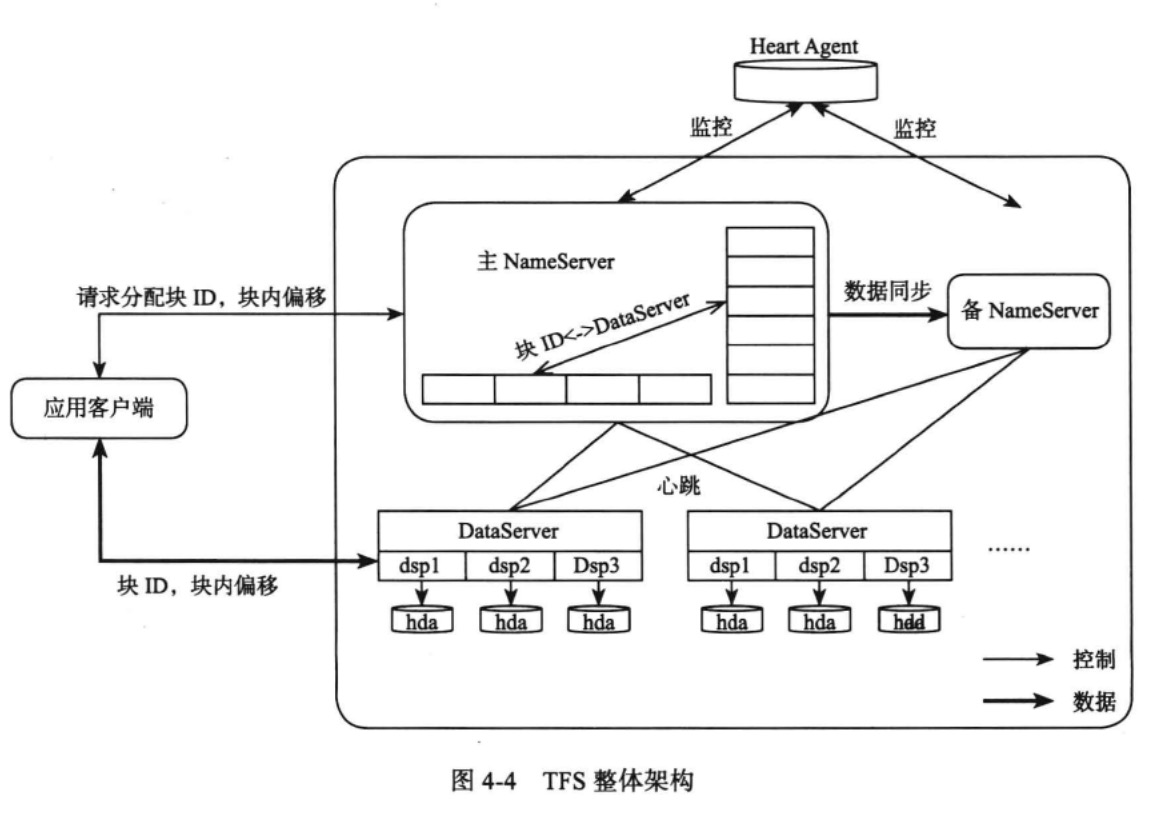
一个TFS集群由两个NameServer和多个DataServer节点组成,NameServer通过心跳对DataServer的状态进行检测。
不是租约,说明不需要对DataServer下放写权限?
答:当要写入的DataServer宕机时,Client告知NameServer,由NameServer重新进行分配。因为TFS读多写少,不需要支持并发写,因此不会有同一个文件对多个DataServer同时写入的情况。
当主NameServer宕机的时候,可以被心跳守护检测出来并将服务切换到备NameServer。
每个DataServer上会运行多个dsp进程,一个dsp对应一个挂载点,这个挂载点一般对应一个独立磁盘,从而管理多块磁盘。
在TFS中,将大量的小文件合并成一个大文件,这个大文件称为块(Block),每个Block拥有在集群内唯一的编号(块ID),通过<块ID,块偏移>这样的映射关系,可以唯一确定一个文件。
与GFS相同,每个块的大小约为64MB,并默认保存三份。且在客户端也缓存NameServer的元数据信息。
追加流程
GFS为了减少对Master的压力,引入了租约机制,从而将修改权限下放到主ChunkServer。TFS是读多写少,且写多是追加写而不是修改。(浏览用户多,商户修改不频繁),因此每次写操作都需要经过NameServer,从而减少系统复杂度。
TFS也不需要支持多客户端并发写,同一时刻每个Block只能有一个写操作,多个客户端的写操作会被串行化
是因为进行写操作的多是商家/管理人员,而这些用户对响应的要求比浏览商品的客户要低很多
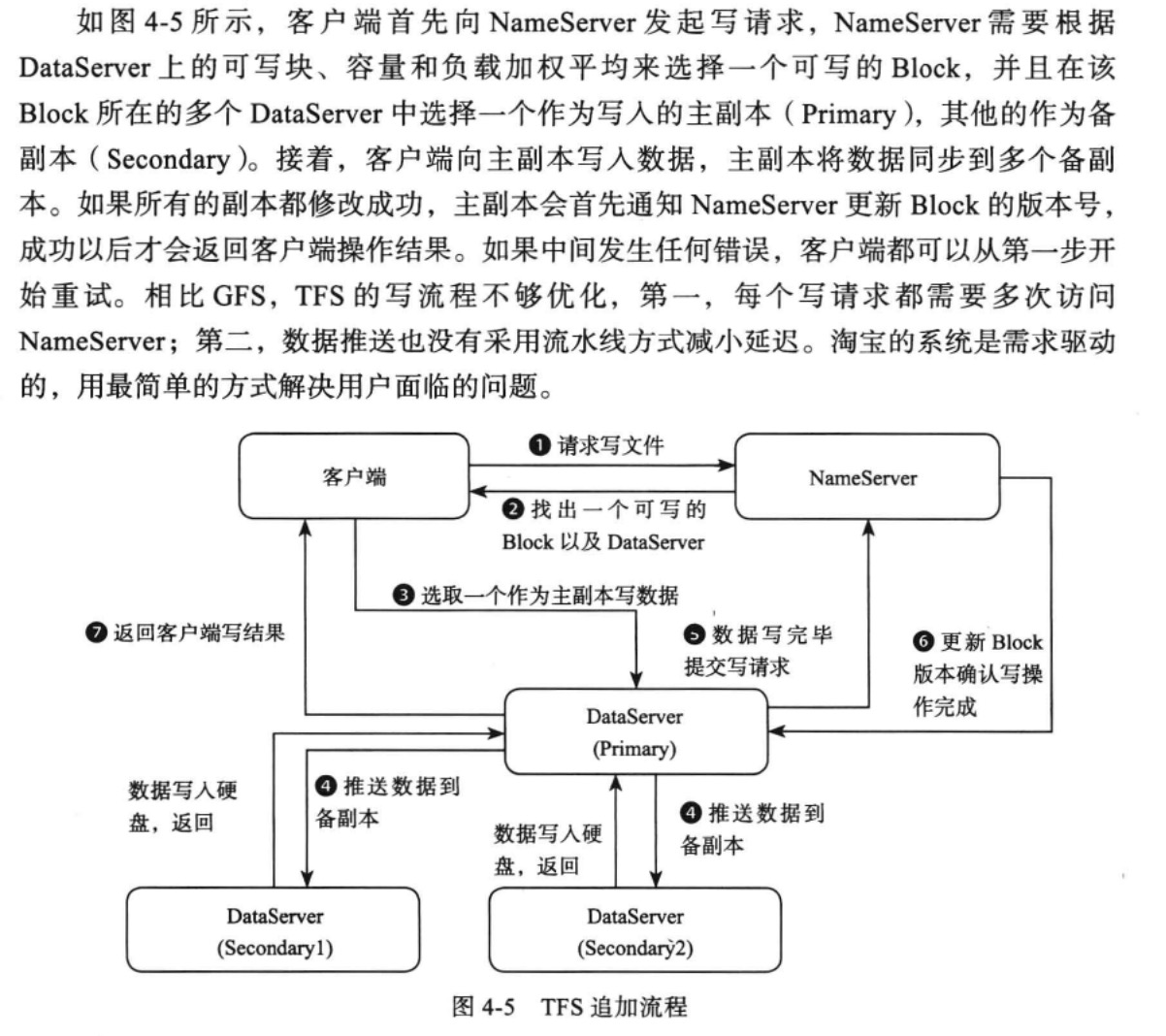
与GFS不同的地方在于:写入操作只有一种,即写入一个文件,而GFS有追加写和大文件写入这两种情况;NameServer参与度比GFS要高很多,在GFS中,在ChunkServer写入完成后chunk的变化不会立刻同步到master,而是在chunkserver定时发往master的信息中携带。但在TFS中写入完成后需要立刻通知NameServer元数据的修改。这应该是要考虑到商家上传好图片之类的信息后需要立马生效看到效果这样实际的业务需求来设计的。即读多写少的情况,这种情况下会有客户端还没有收到写入成功的消息但是其他用户就能够看到这张图片了,用最快的速度提高图片的生效时间。
在写入完成后DataServer会返回客户端两个信息:小文件在TFS中的block编号以及在block中的偏移。引用系统在读取图片的时候能保证在所有block中他的偏移量都是有效的。
这里的一致性要求就比GFS高了,GFS只是保证数据至少有一次写入,且就算是同一个chunk的不同备份,数据的偏移量都可能不一致,因为他们对每一个chunk块都维护了一个元数据结构。而TFS则为了保证应用层面的简单,强制要求任何一个block备份块都能使用同一个小文件的偏移量。即主备block之间所有字节都一致。
NameServer

之所以不需要维护文件与Block之间的映射关系是因为block与文件的关联关系已经返回给客户端另行保存了。
DataServer掉线以及新加入的操作都跟GFS一样。
讨论
图片应用有几个问题:
- 图片去重
- 图片更新与删除


保证每个block都能使用同一个物理偏移带来架构简化的同时也意味着无法随便对block做垃圾回收、合并等操作。
Facebook Haystack
Facebook相册后端早期采用基于NAS的存储,通过NFS挂载NAS中的照片文件来提供服务。后台出于性能考虑,自主研发了Facebook Haystack。
系统架构
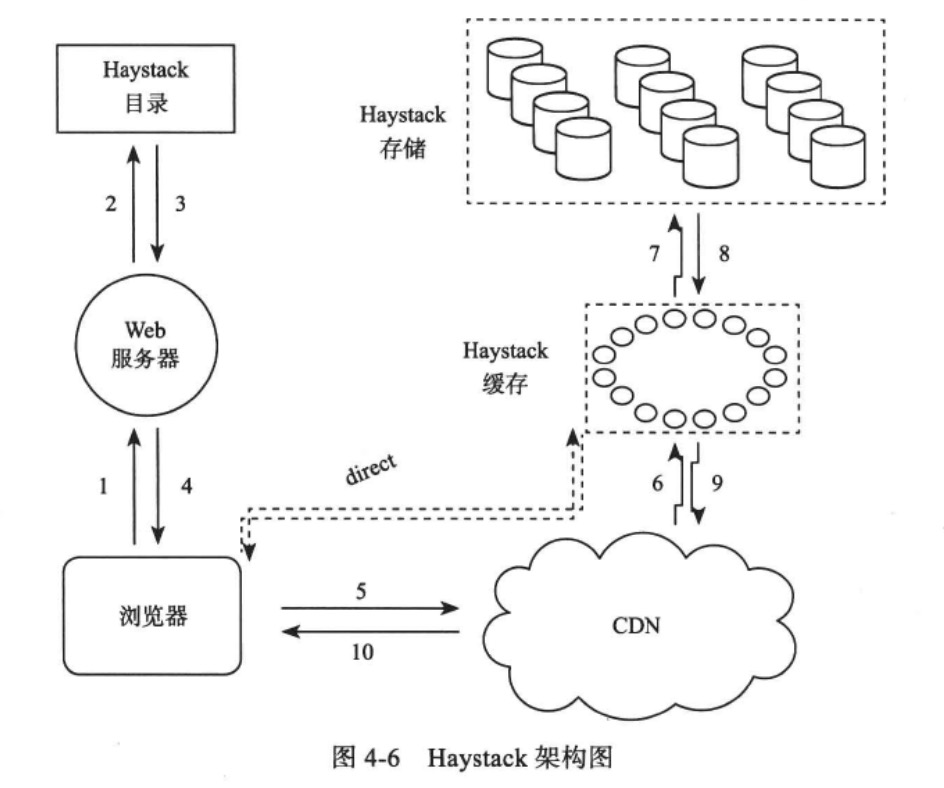
FH的思路与TFS类似,也是多个逻辑文件共享一个物理文件。
Haystack系统包括三个部分:目录、存储、缓存。
Haystack存储是物理节点,以物理卷轴(physical volume)的形式组织存储空间,每个物理卷轴一般都很大(100GB),这样10TB的数据也只需要100个物理卷轴。
每个物理卷轴对应一个物理文件,因此,每个存储节点上的物理文件元数据都很小。
将基础的数据块变大了,相应的对块的管理就减少了
多个物理存储节点上的物理卷轴组成一个逻辑卷轴,用于备份。
Haystack目录存放逻辑卷轴和物理卷轴的对应关系,以及照片id到逻辑卷轴之间的映射关系。
Haystack缓存主要用于解决对CDN提供商过于依赖的问题,提供最近增加的照片缓存服务。
写流程
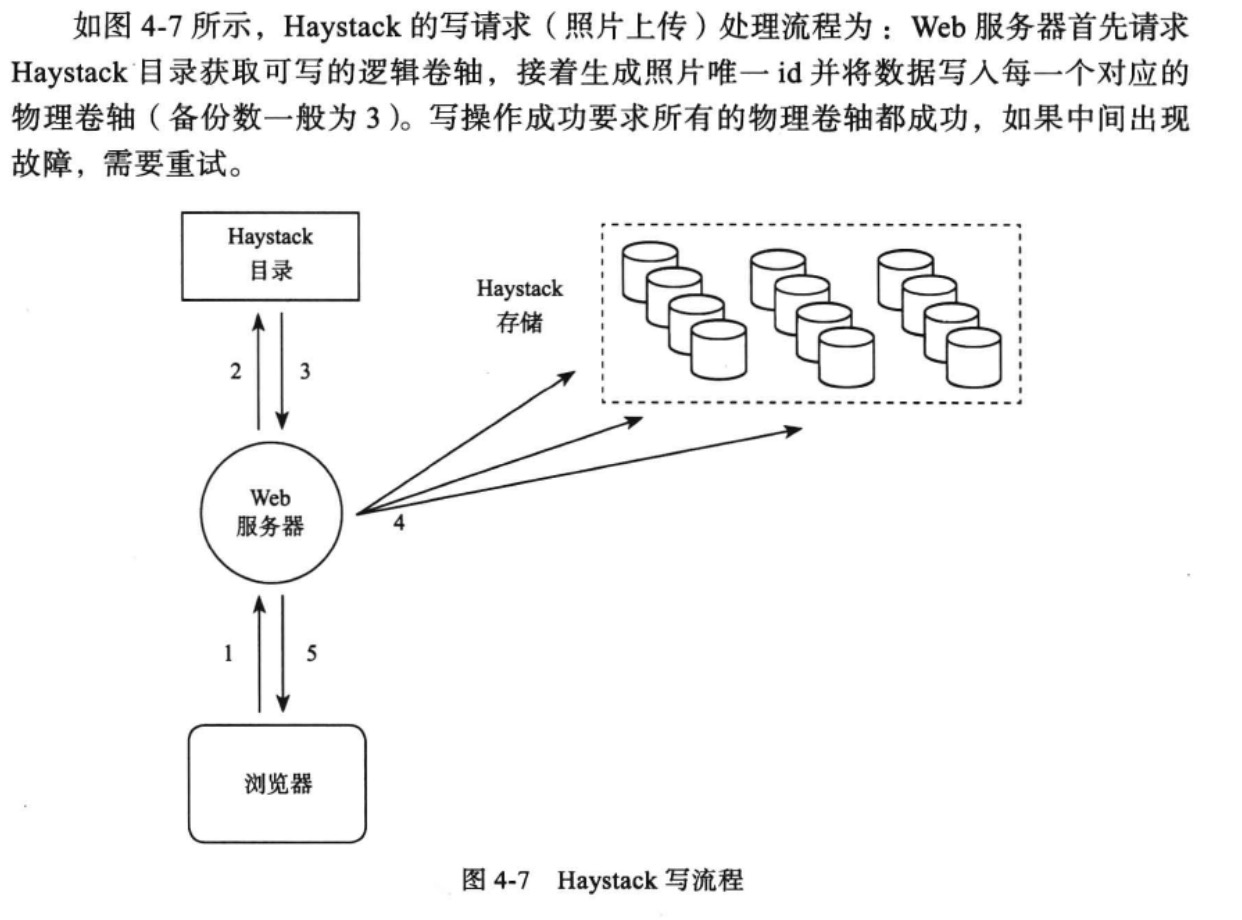
这样的话存储端需要跟Haystack目录有一个通信过程,这样才能保证目录的准确性,且相关的元数据位于Hatstack目录。这里的Web服务器就承担了GFS与TFS中的客户端的功能:他先从Haystsck目录中寻找有效的逻辑目录以及对应的物理存储信息,然后将生成id的图片写入存储端。
Haystack的一致性模型只保证写操作成功,逻辑卷轴对应的所有物理卷轴都存在一个有效的照片文件,但有效照片文件在不同物理卷轴中的偏移量可能不同。
这个就类似GFS的一致性模型,即保证数据被写入,但不能保证写入的地方是一致的。这样就不能用TFS一样一个文件ID查询所有副本,需要在另外维护一个文件ID与数据在各个块中的偏移量信息的映射结构。
Haystack只能追加不能更改照片,如果有修改,则新增一条照片ID并将旧的ID替换。如果新的照片和原有照片不在同一个逻辑卷轴,Haystack目录的元数据会更新为最新的逻辑卷轴;如果新增照片和原有的照片在相同的逻辑卷轴,Haystack存储会以偏移更大的照片文件为准。
按照用户-逻辑卷轴-物理卷轴。这样的分层结构,对照片修改后如果在同一个逻辑卷轴内,则只需要修改用户-逻辑卷轴部分对于<图片id, 逻辑卷轴>这个映射关系即可。如果不在同一个逻辑卷轴内,则需要修改整体的元数据结构。 ?
容错处理
Haystack存储节点容错:
Haystack目录容错:
也就是说Haystack实际上是将元数据持久化到数据库中,将保证元数据写入磁盘的工作交给了数据库。
Haystack存储
Haystack存储保存物理卷轴,每个物理卷轴对应文件系统中的一个物理文件,每个物理文件格式如下: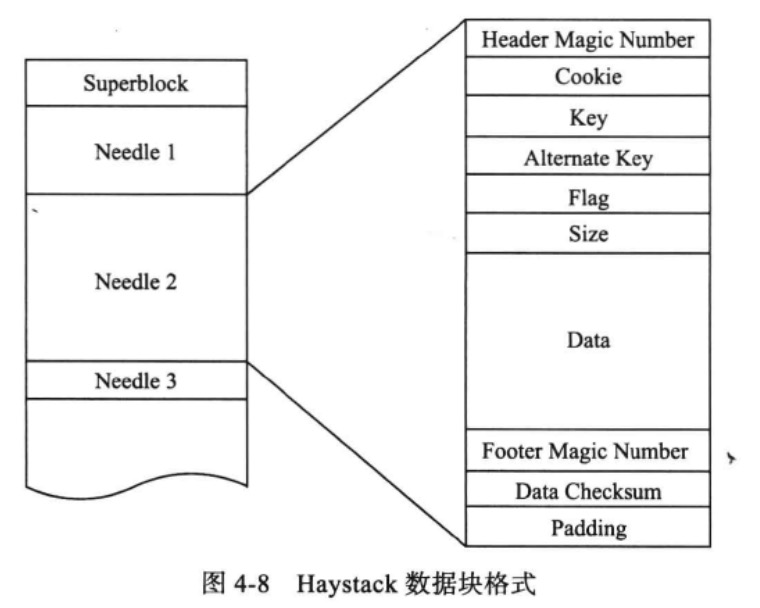
多个照片存放在一个物理卷轴中,每个照片文件是一个Needle,包含实际数据以及逻辑照片文件的元数据。部分元数据需要装载到内存中用于照片查找,包括Key(照片ID,8字节),Alternate Key(照片规格,4字节),照片在物理卷轴的偏移Offset(4字节),照片的大小(4字节),每张照片的信息需要占用20字节空间。假设每张照片大小为80KB。则一台可用磁盘为8TB的机器可以保存8TB/80KB=1亿张照片,占用内存1亿x20字节=2GB。
这样的存储设计是基于机器的硬件而生,以硬件上的物理卷轴为基本块用于存储信息。好处是数据集中且由于写入都是在一块物理卷轴中写入,不会有磁盘指针跨磁道的开销,写入快速。
存储节点宕机时,需要恢复内存中的逻辑照片查找表,扫描整个物理卷轴耗时太长,因此对每个物理卷轴维护了一个索引文件,保存每个Needle查找相关的元数据。
这部分元数据既持久化到Needle中和图片数据放一起,又单独持久化为一个索引文件。说明元数据的维护可能并不需要Haystack目录保存到自己本地,只需要等待存储节点将自身的物理卷轴元数据加载到内存中后发送给Haystack目录即可。
由于更新索引文件的操作是异步的,所以可能出现索引文件和物理卷轴文件不一致的情况,不过由于对物理卷轴文件和索引文件的操作都是追加操作,只需要扫描物理卷轴文件最后写入的几个Needle,然后补全索引文件即可,这只能在只有追加写入的系统中才能使用,也很常用。
系统保证会将文件写入,并在写入完成后修改索引文件,但这一步就已经属于异步操作,所以只会出现索引文件缺失而不是索引文件中存在,但是物理卷轴中没有的情况。索引文件缺失的这部分通过对操作日志的重现可以恢复。

既然不需要跟TFS一样保证一个ID都能从所有副本中得到一样的数据,那么就一定会有一个文件ID与物理卷轴偏移量的映射数据结构,这样就可以对存储节点采用垃圾回收策略。而他的策略和其他系统一样都是删除已删除的和重复的数据
讨论
Haystack与TFS最大的不同就在与他可以进行垃圾回收。
Haystack使用RAID6,并且底层文件系统使用性能更好的XFS,TFS不使用RAID机制,文件系统使用Ext3,由应用程序负责管理多个磁盘。
看起来就像Facebook不差钱一样,无论是GFS还是TFS都是考虑系统建立在不稳定廉价的硬件基础上,因此他们对于存储节点出现故障的频率是考虑很高的,所以在对文件块的设计上,偏向于小巧轻便,这样当存储节点宕机无法恢复的时候可以快速地对其他副本进行复制备份,且不会对现有业务造成影响 。而Haystack的大块设计,既简化了元数据与磁盘管理开销,但同时增加了磁盘成本与维护成本,每当存储节点宕机切无法恢复时,数据迁移备份的时间会长很多。
内容分发网络(CDN)

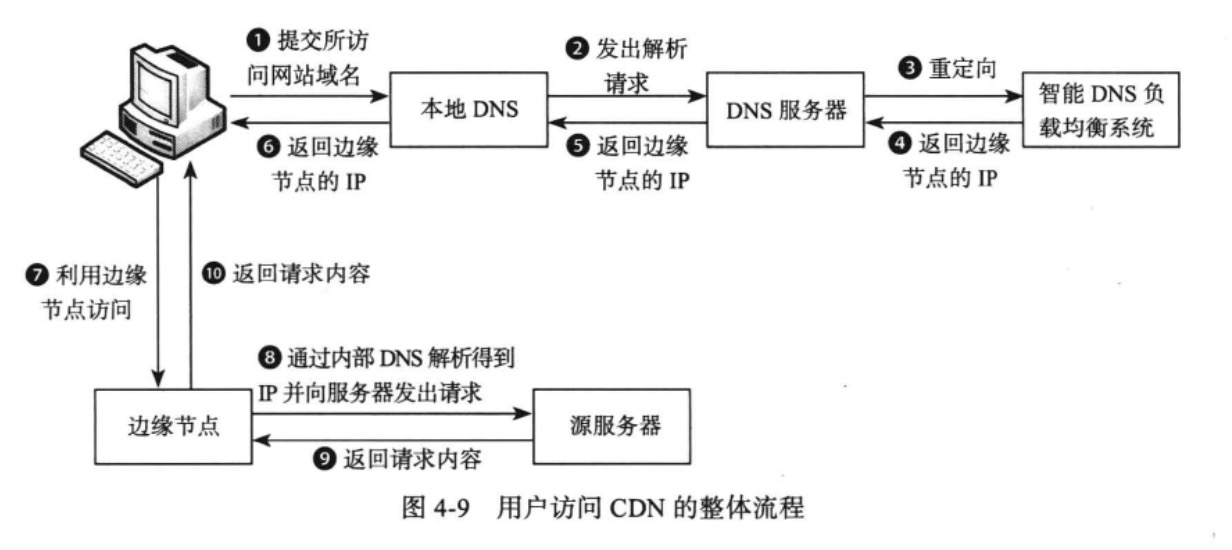
CDN架构
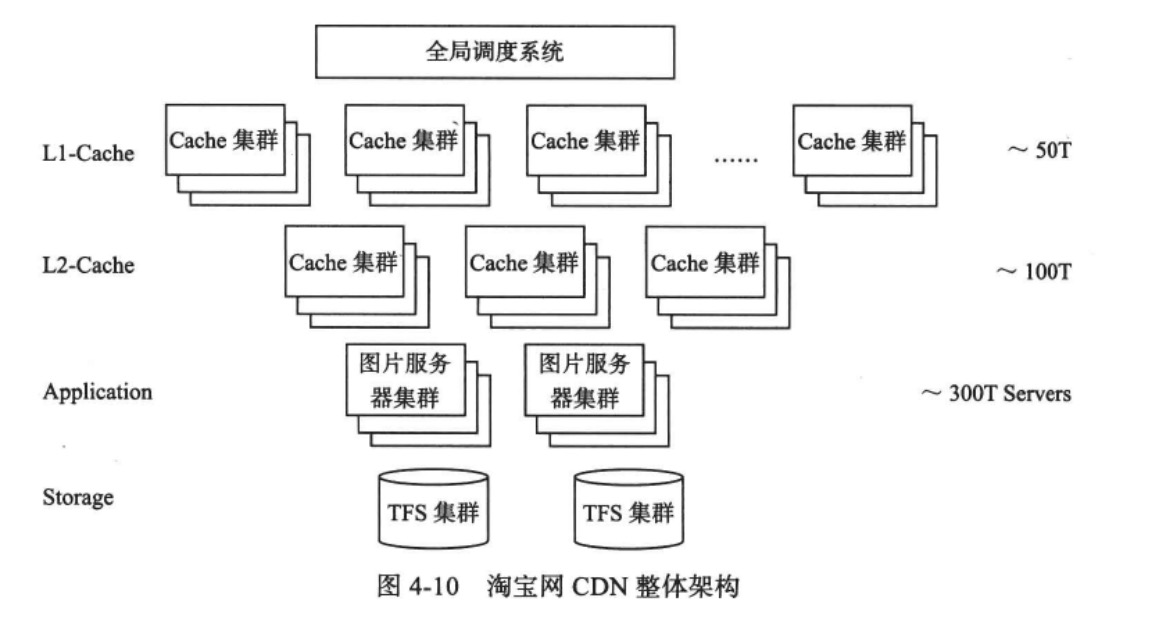
图片存储在后台的TFS集群中,CDN系统将这些图片缓存到离用户最近的边缘节点。
CDN采用两级Cache:L1-Cache以及L2-Cache。
用户访问淘宝网的图片时,通过全局调度系统调度到某个L1-Cache节点。如果L1-Cache节点命中,那么直接讲图片数据返回用户;否则,请求L2-Cache节点,并将返回的图片数据缓存到L1-Cache节点;否则,请求源服务器的图片服务器集群。
每台图片服务器是一个运行着Nginx的Web服务器,他还会在本地缓存图片,只有当本地缓存也不命中时才会请求后端的TFS集群。
对于每个CDN节点,其架构如图所示: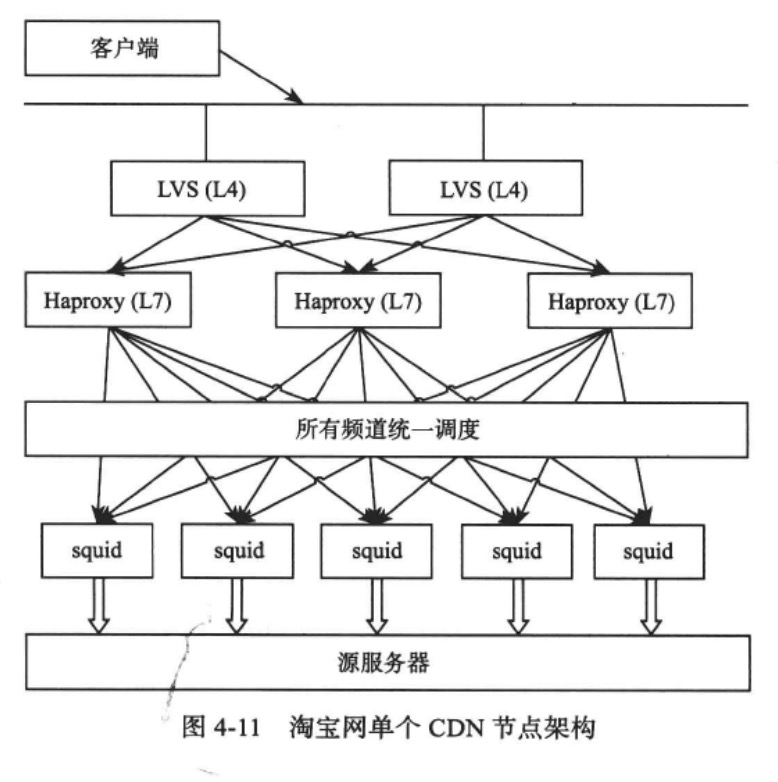
每个CDN节点内部通过LVS+Haproxy的方式进行负载均衡。
其中LVS是四层负载均衡软件,性能好;Haproxy是七层负载均衡软件,能够支持更加灵活的负载均衡策略。通过有机结合两者,可以将不同的图片请求调度到不同的Squid服务器。
Squid服务器用来缓存Blob图片呢数据。用户的请求按照一定的策略发送给某台Squid服务器,如果缓存命中则直接返回;否则Squid服务器首先会请求源服务器获取图片缓存到本地,接着再将图片数据返回给用户。
相比起分布式存储系统,分布式缓存系统的实现要容易得多,这是因为缓存系统不需要考虑数据持久化,如果缓存服务器出现故障,只需要简单地将其从集群中删除即可。
分级存储
分级存储是淘宝CDN架构的一个很大创新。
由于缓存数据有较高的局部性,在Squid服务器上使用SSD+SAS+SATA混合存储,图片随着热点变化而迁移,最热门的部署到SSD,中等热门的部署到SAS,轻度热门的存储到SATA。
结合数据的访问频繁程度与存储介质的访问速度分多级存储,能够加快数据访问速度。
低功耗服务器定制
淘宝CDN架构的另一个亮点是低功耗服务器定制。
CDN缓存服务是IO密集型服务而不是CPU密集型,因此可以选用CPU功耗相对较低的服务器。
讨论
Blob存储系统读访问量大,更新和删除很少,特别适合通过CDN技术分发到离用户最近的节点。
CDN也是一种缓存,需要考虑与源服务器之间的一致性。如果源服务器删除了Blob数据,需要能够比较实时地推送到CDN缓存节点,否则只能等待缓存节点中的对象被自然淘汰,但是对象的有效期往往很长,热门对象很难被淘汰。
可以专门维护一个专门用于接收这种修改与删除操作的程序。但是如果边缘节点很多的情况,光修改一次图片就要使得TFS应用或者上层的应用通知每一个squid服务器,这些工作量会很耗时且浪费资源。或许可以采用GFS中的那种串行化设计,TFS只需要通知离他最近的几台squid服务器,然后让这几台squid服务器继续往外分发修改事件,缓存系统也不需要担心重复删除/修改等问题。
随着硬件技术的发展,SSD价格的下降,新上线的CDN可以全部配制成SSD。