这是一篇在阅读《大规模分布式存储系统:原理解析与架构实战》时的阅读笔记,由于长时间碎片阅读的关系导致在做这种读书笔记的时候接近复制粘贴。虽然其中会有一小部分自己的想法但都十分零碎,希望后续能改进。
分布式文件系统的主要功能有两个:

Google文件系统(GFS)

系统架构
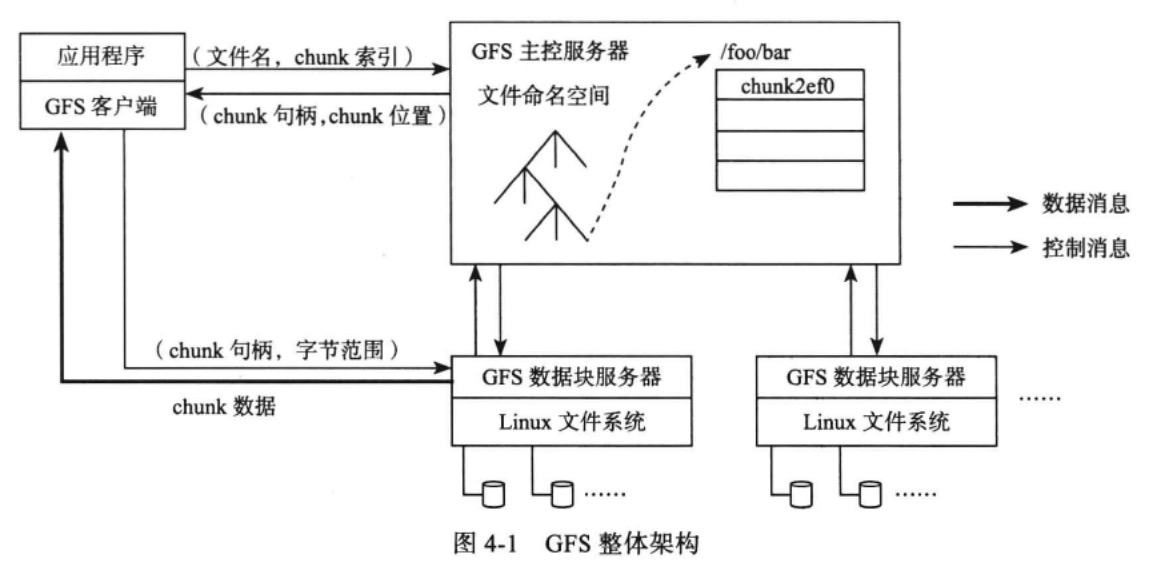
GFS可分为三种角色:GFS Master(主控服务器)、GFS ChunkServer(CS,数据块服务器)、GFS客户端。
GFS的文件被划分为固定大小的文件块,并拥有一个全局唯一的64位chunk句柄(类似于uuid),chunk被以普通linux文件形式保存在服务器中,并在不同机器中复制多份,默认为三份。
主控服务器中维护了系统的元数据(包括文件及chunk命名空间、文件到chunk之间的映射、chunk位置信息)。它也负责整个系统的全局控制(如chunk租约管理、垃圾回收无用chunk、chunk复制等)。主控服务器会定期与CS通过心跳的方式交换信息。
既然是通过租约实现对chunk server的存活检测,那这个心跳应该都是chunk server发往master.
PS:找了一下论文果然如此,chunk server定时往master发送自身chunk相关信息。这样这部分数据就不需要让master持久化到自身,而是可以通过与chunk server的通信从提交的信息中构建
客户端是提供给应用程序的访问接口,他是一组专用接口,不遵循POSIX规范,以库文件的形式提供。客户端访问GFS时先从master获取对应文件的句柄与chunk的字节范围。然后client与chunk server直接通信。最大程度减少master的负担。
GFS不缓存文件数据,只缓存元数据信息。这是由GFS应用的特点决定的:MapReduce与Bigtable。
- MapReduce:GFS客户端使用方式为顺序读写,没有缓存文件数据的必要
- Bigtable:Bigtable作为分布式表格系统,内部已经实现了一套缓存机制。
如何维护客户端缓存与实际数据之间的一致性是一个及其复杂的问题。
关键问题
租约机制
GFS数据追加以记录为单位,每个记录的大小为几十KB到几MB不等,如果每次记录追加都需要请求Master,那么Master显然会成为系统的性能瓶颈,因此,GFS系统中通过租约(lease)机制将chunk写操作授权给ChunkServer。拥有租约授权的ChunkServer称为主ChunkServer,其他副本所在的ChunkServer称为备ChunkServer。
租约授权针对单个chunk,在租约有效期内,对该chunk的写操作都由ChunkServer负责,从而减轻Master的负载。
Q:如果主ChunkServer在租约有效期内下线该怎么办?
1: 客户端如果多次请求ChunkServer失败,则重新往Master申请这个文件块的新的ChunkServer,如果Master确认在租约有效期内原先的主ChunkServer依旧无法上线,则在现有备份ChunkServer中要么直接选择要么通过选举的方式重新赋予一个备ChunkServer权限使其对Client服务。
2:客户端判断在租约有效期内依旧无法联系上ChunkServer,那么在此之前,Master返回文件命名空间以及chunk相关信息的时候顺便携带chunk的备份服务器信息,那么就让Client发起选举(如果由Client直接选择,那么如果有多台Client同时读写同一个数据块,那么将会出现复数个Proposer)【这个操作不行,只能有一个Proposer,否则这是没意义的】
一般来说,由于涉及文件读写,所以租约有效期比较长为60秒所有。
直接删除并重新备份,减少了运行期间chunk数据重新保持一致的工作量,过于复杂会使得出问题的几率增加。且同步数据的工程量比直接复制要大。
一致性模型
GFS主要是为了追加写(append)而不是改写(overwrite)而设计的,一方面改写的需求比较少,或者可以通过追加来实现,比如可以只使用GFS的追加功能构建分布式表格系统Bigtable;另一方面是因为追加的一致性模型相比改写要更加简单有效。
追加写时,如果成功那万事大吉。如果有些chunkserver写入成功而有些写入失败,失败的副本可能会出现一些可识别的填充(padding)记录。GFS客户端追加失败将重试,只要返回用户追加成功,说明在所有副本中都至少追加成功了一次,也有可能一个chunk被追加了多次,即重复记录;也可能出现一些可识别的填充记录,需要在应用层处理这些问题。
GFS只负责写入数据成功,但不能保证写入数据的完整性以及物理层面的一致性。即它能确保chunk的所有副本都已经被写入数据,但不能确保所有的数据都一致(这里的一致是指所有的数据都是完整一条。有的chunkserver成功写入数据但是会有重复记录,有些chunkserver写入一些可识别的填充记录。)
如果要保证强一致性,那么当某个chunkserver长时间无法响应的时候,client的整个写入都会被阻塞,此时应该添加一个超时机制,如果长时间没有响应,则client重新发起写入请求,这种情况下就容易产生重复数据。

但是每次写入都会返回这部分文件位于chunk的那一部分,需要读取的时候只需要根据这些文件偏移量信息读取即可,而且在chunkserver的写入过程中需要保证原子性,即每个请求的写入不能被打断,但是同一client的写入请求可以被打断。

追加流程
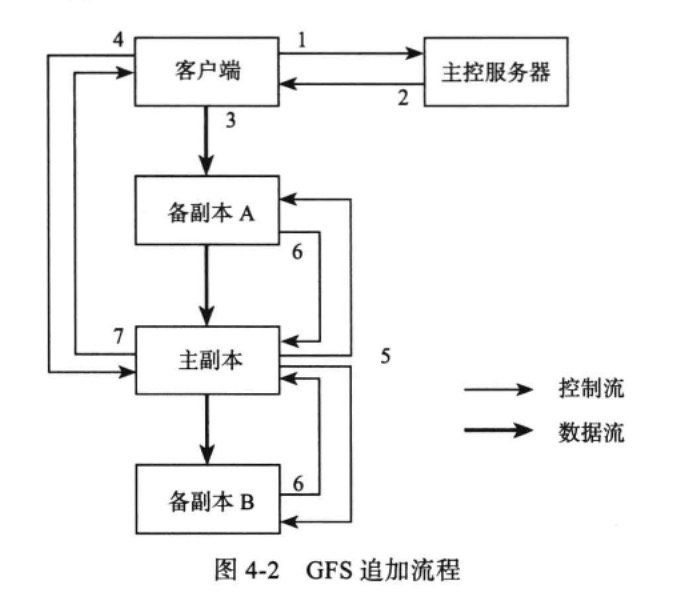

client在给主chunkserver发送写请求的时候,其他备chunkserver数据还缓存在内存中,如果同时有多个写操作将数据缓存在一台chunkserver服务器中或者client没有发送写请求给主chunkserver或者主chunkserver没有发送写请求给备chunkserver,就会出现内存溢出等问题。
解决办法就是在chunkserver中维护一条LRU,如果某段数据长时间没有被写入则会排到队列末尾并被移除。
客户端这里并没有在写入完成后将修改元数据的请求发往Master,这部分修改是在ChunkServer定时发往Master的信息中携带的。也就是说master的元数据变更会比chunk server实际文件变更延后一段时间。
如果在发送写请求的时候备ChunkServer宕机了该怎么办?
这时候主ChunkServer发起写入请求会失败,则通知Master将下线的ChunkServer中的数据进行垃圾回收,并将其中的数据重新备份。
如果在发送写请求的时候是主ChunkServer宕机了该怎么办?
Client应该通知Master在超过租约时限后重新在备ChunkServer中选出主ChunkServer并重新开始写入流程。

这样的要求ChunkServer自身需要维护其chunk的所有备份信息。
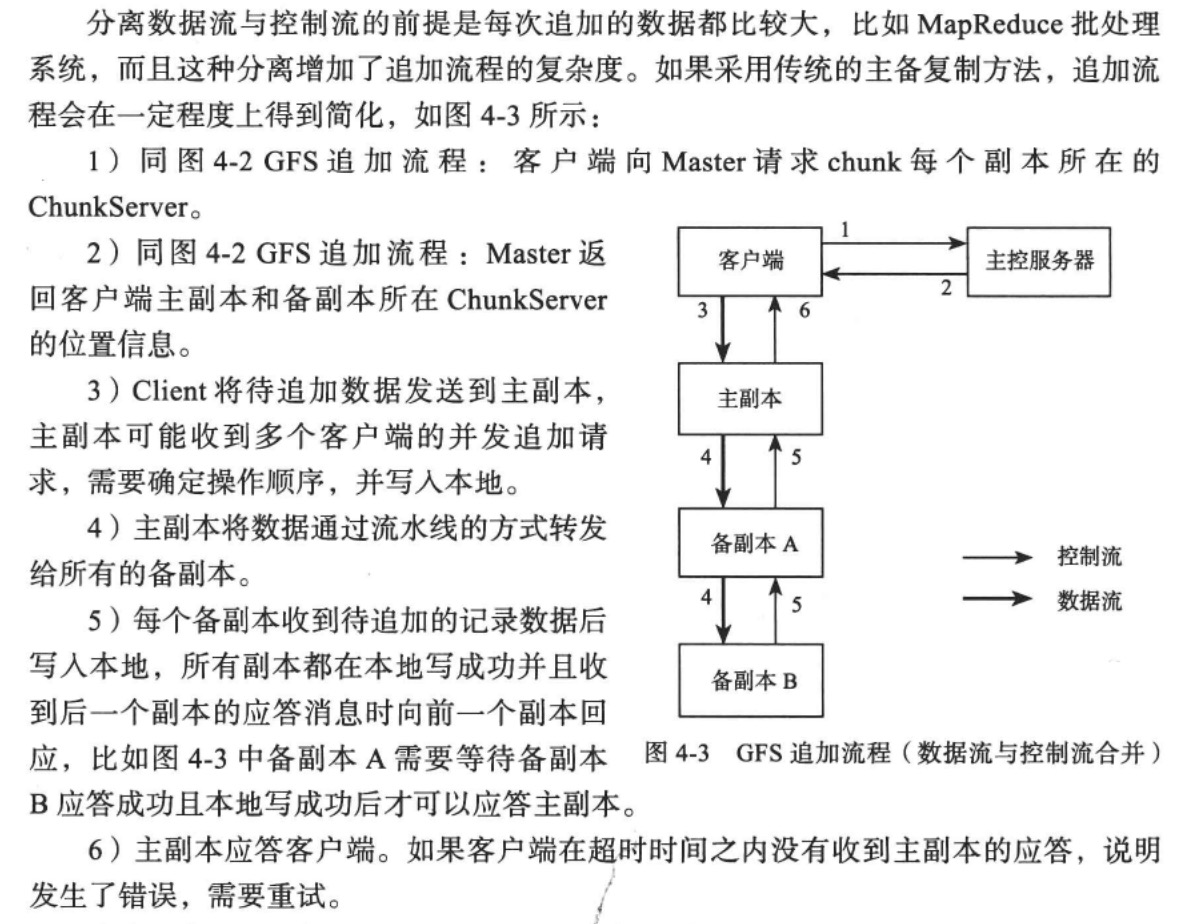
如果在追加过程中主ChunkServer租约过期而失去chunk修改操作的权限改怎么办?
主ChunkServer应该要向Master续租,如果续租失败,为了保证流程规范,此次写入应该判定为失败,并让客户端重新向Master请求,由Master选举出新的主ChunkServer。
这里说的是写入主ChunkServer,但是前面又说写入最近的ChunkServer并由最近的ChunkServer转发给其他ChunkServer。他们的区别是什么呢?
答:可能是数据量的不同,如果是追加流程且数据量较小的情况下,只需要由客户端发送给最近的ChunkServer并由他进行转发,或者发送给所有的ChunkServer,并将写入命令发给主ChunkServer即可。如果是大文件写入,则需要按照上述流程进行大文件转发。相关链接
2020-03-15追加:就是数据量的不同,最开始的那种数据流与控制流分离的做法适用于数据量大的情况,这可以减少数据传输对整个系统的影响,但会使得写入流程变得更加复杂
容错机制
Master容错
Master容错与传统方法类似,通过操作日志加checkpoint的方式进行,并且有一台被称为“Shadow Master”的实时热备。
Master需要持久化前两种元数据。对于第三种元数据,可以交给ChunkServer维护,当ChunkServer上线的时候将这些信息发送给Master。
GFS Master的修改操作总是先记录操作日志,然后修改内存。当Master发生故障时,可以通过磁盘中的操作日志恢复内存数据结构。
为了减少Master宕机恢复时间,Master会定期将内存中的数据以checkpoint文件的形式转储到磁盘中,从而减少回放的日志量。
Master的任何修改元数据的操作都必须在实时热备中完成后才能生效。Shadow Master通过日志的形式接收Master的操作步骤,并在自己的内存中回放这些元数据操作。
为了保证同一时刻只有一台Master工作,是否为主Master需要通过选举得到。
如果热备服务器宕机了导致Master始终无法写入成功该怎么办?
如果允许也可以部署两台热备服务器。另一种方法就是Master将日志同步记录保存下来,当热备服务器上线后将之前的操作重新发给热备服务器。
ChunkServer容错
GFS采取复制多个副本的方式实现ChunkServer的容错,每个chunk由多个存储副本,分别存储在不同的ChunkServer上。
对于每个chunk,必须都要写入成功才算整个写入流程成功。如果相关副本丢失或者服务器下线的情况,Master会将其上的副本重新复制,并且当这台服务器重新上线的时候他的数据会被垃圾回收,因为此时它上面的数据都有可能与其他副本不一致。
这部分数据也将会被视为垃圾,并在合适的时候进行回收。
这样来看chunk中会存储很多垃圾数据:重复写入的数据、可读取的填充数据、错误数据、已删除的数据。如果放任这些数据积累,可能会造成空间的浪费,GFS是否有类似于Bitcask的垃圾回收机制或者LevelDB的SSTable合并机制用于清理垃圾?
答:有,GFS采用惰性回收的方式进行垃圾回收。在删除文件的时候会将文件的元数据做一个标记,master会在合适的时候扫描所有chunk的namespace并重新整理chunk。这里就应该会将已删除的数据、重复写入的数据、可读取的填充数据、错误数据清除。
看文章说的都是已删除数据,其他垃圾数据不知道会不会清楚,不过我想应该会的吧,毕竟成本放那里,能省一点是一点。
Master设计
Master内存占用
内存是Master的稀有资源。chunnk的原信息包括全局唯一的ID、版本号、每个副本所在的chunkserver等。
负载均衡

系统中需要创建chunk副本的情况有三种:chunk创建、chunk复制、负载均衡。
第二点就是为了后续的文件写入预留出空间,否则都用来存储chunk而没有空间写入,就使得添加新的服务器对分布式存储系统的性能毫无提升。
当chunk的数量低于一定的数量以后,Master会尝试重新复制一个chunk副本。可能的原因包括:ChunkServer宕机、ChunkServer报告Chunk副本损坏,ChunkServer磁盘故障等。
每个chunk复制任务都有优先级,按照优先级从高到低在Master队列排队等待执行。
这个优先级应该是按照chunk的热度与数量来划分的,如果某个chunk的数据访问量高,那么为了保证后续的写操作,则优先将其备份。或者某一个chunk只剩一个副本,为了保证数据不丢失,则也要优先将其备份。而热度与数量之间我认为以数量为优先。因为chunk整块丢失是无法自动化恢复的,且无法保证完全恢复,而热度方面还有其他备用块分担压力。
当client要写入到一个只有一个副本的chunk块的时候,GFS将会阻塞其操作,并规定必须要有两个副本才可以,此时chunkserver会将这个情况报告给master用于提高这个chunk块的复制优先级。
就跟我上面猜想的一样,一个副本的时候已经很危险了,为了防止操作对现有chunk块造成不可逆的影响,需要优先保证副本的数量。
Master会定期扫描当前副本的分布情况,如果发现磁盘使用量或者机器负载不均衡,将会执行重新负载均衡操作。
这个操作应该就是将磁盘压力大的chunk复制到磁盘使用量少的服务器上,并将原来的chunk删除。

垃圾回收

对于那些下线后的没有执行删除的chunkserver,master会维护一个递增的版本号,当检测到版本号过期时一样会将chunk的空间内释放。
快照(Snapshot)
快照操作是对源文件 / 目录进行一个“快照操作”,生成该时刻源文件根目录的一个瞬间状态存放于目标文件根目录中。
GFS采用标准的写时复制技术,“快照”只是增加GFS中chunk引用计数,表示这个chunk被快照文件引用 了,等到客户端修改这个chunk时,才需要在chunkserver中拷贝chunk的数据生成新的chunnk,后续的修改操作落到新生成的chunk上。
也就是说这里的快照不仅仅是对master元数据的快照,还是对当前目录下所有文件做的快照,当快照完成后后续的读写工作都将会在新的chunk中执行。类似于做了一个完整的目录下的所有文件备份工作。



快照相当于给所有chunk做一个标记(体现在引用计数大于1),并当gfs需要对这个chunk进行操作的时候再复制该chunk进行备份,这里可能会有一个情况就是后续只写入C3,那么foo的chunk将会有C1、C2、C3、C3’这四种。此时如果C1丢失,那么快照也随之失效了。
ChunkServer设计

新建的之后直接在旧的chunk上覆盖写即可。这样也就解决了上面提到的如何回收除了删除文件之外的那种重复数据、填充数据、错误数据等办法。不需要将其做具体区分,只需要按chunk进行整块删除,并在后续新数据写入的时候直接覆盖即可。

总结
谷歌用GFS证明了单总控节点在面对现代数据处理的情况下是可行的,既保证了原子性又容易实现。这里的原子性属于“保证至少有一次写入/记录至少原子性追加一次”,即一次写入数据可能会有重复写入的问题,但这个问题交给应用层面解决,浪费的空间在当chunk块删除的时候会被直接覆盖。
通过租约的方式将对chunk的修改授权下放到ChunkServer从而减少了Master的负载,通过流水线的方式复制多个副本以减少延时,追加流程复杂繁琐。需要设计高效简介的元数据模型,并且要支持快照操作。支持写时复制的B数能够满足Master日常管理元数据所需,这里的实现相当复杂。