这是一篇在阅读《大规模分布式存储系统:原理解析与架构实战》时的阅读笔记,由于长时间碎片阅读的关系导致在做这种读书笔记的时候接近复制粘贴。虽然其中会有一小部分自己的想法但都十分零碎,希望后续能改进。
NoSQL=Not Only SQL
关系数据库在海量数据场景面临以下挑战:
- 事务:关系模型要求多个SQL操作满足ACID特性,但是在分布式系统中,如果要满足该特性,需要用到两段提交协议,这个协议性能很低,且不能容忍服务器故障。
- 连表:传统数据库设计需要满足范式需求,第三范式规定两张关联的表中除了主键外不允许出现其他冗余字段,但是随着表数据增加,连表的开销也就随之增大。为了避免这个问题往往采用数据冗余的方法。
- 性能:关系数据库采用B/B+树存储引擎,更新操作的性能不如LSM树这样的存储引擎(在更新了磁盘上数据的同时也要根据新的数据更新索引树,在大量数据的情况下对索引的更新开销会很大),对基于主键的增删改查操作性能不如定制的K-V存储系统
NoSQL系统面临的问题:
- 缺少统一标准:关系数据库有SQL语言这样的业界标准,并拥有完整的生态链,而NoSQL系统使用方法不同,切换成本高,很难通用。
- 使用以及运维复杂:NoSQL的使用需要理解系统的实现,关系数据库有完整的运维工具与大量经验丰富的运维人员。
着重理解关系数据库的原理与NoSQL的高可扩展性。
事务与并发控制:
事务拥有ACID属性,最理想的状态就是每个事务互不干扰,按顺序执行,这被称为可串行化。但可串行化效率低下,商业数据库通常有多种不同的隔离级别。
事务的并发控制通过锁机制来实现,锁会有不同的粒度:行、数据块、表
互联网应用中读事务比例远高于写事务,因此使用写时复制或者多版本并发控制技术来避免写事务阻塞读事务。
事务
事务是数据库操作的基本单位,因为他们具有ACID(原子性、一致性、隔离性、持久化)特性。
- 原子性:使得事务一定全部完成或者一定全部失败,不允许存在中间状态被感知到。一个事务对同一数据项的多次读取结果一定是相同的(如果存在中间状态被感知到,则在读取的时候会读取到中间状态,导致多次读取的结果不一致)
- 一致性:保证数据符合设定规则,有2个方面来保证。一方面通过数据库内部规则确保数据类型正确,数据的值在给定范围内等;另一方面通过应用程序保证数据的值符合当前场景需求。
- 隔离性:事务的执行不是一步就完成的,因此要确保事务在执行过程中对外不可见。在并发情况下,一个事务在修改途中插入一个查询事务,这个查询事务是感知不到修改事务的中间状态,对他来说数据形式是原始数据,而不是执行过程中修改了一部分的更新事务中的数据。
- 持久性:事务完成/失败后,对数据库的影响是永久性的。(成功的数据修改与失败的错误日志记录)


四种隔离级别会产生不同的读写异常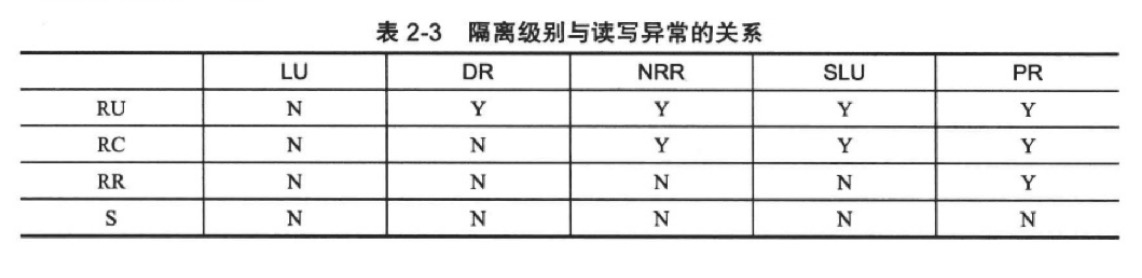
并发控制
数据库锁
数据库的锁分为两类:读锁、写锁
通常只允许对一个元素加一个写锁,可以对一个元素加多个读锁。
写事务通常会阻塞读事务。
多个事务并发执行可能会出现死锁,解决办法有两种:
- 给每个事务设置超时时间
- 设置死锁检测,死锁的原因在于事务之间资源的互相依赖,检测到死锁后可以通过回滚其中某个事务来消除死锁
写时复制:
在执行写操作时复制一份索引树,并在该索引树上操作。
在整棵索引树中只是复制需要修改的部分结点,不会复制整棵索引树。第三步完成的时候旧的索引树中与复制出来的索引树相关的结点指针都指向新的被修改后的部分索引树。
操作顺序:
- 从索引树A中获取到写操作锁涉及的结点B
- 复制B得到C
- 对C进行修改操作
- 提交后,原子性地将A中原本指向B的指针指向C
为了避免内存浪费,需要每个结点都维护一个引用计数器,当计数器为0的时候,该结点被垃圾回收。但是:写时复制操作成本高,且多个写操作的结点如果相交,则是互斥的。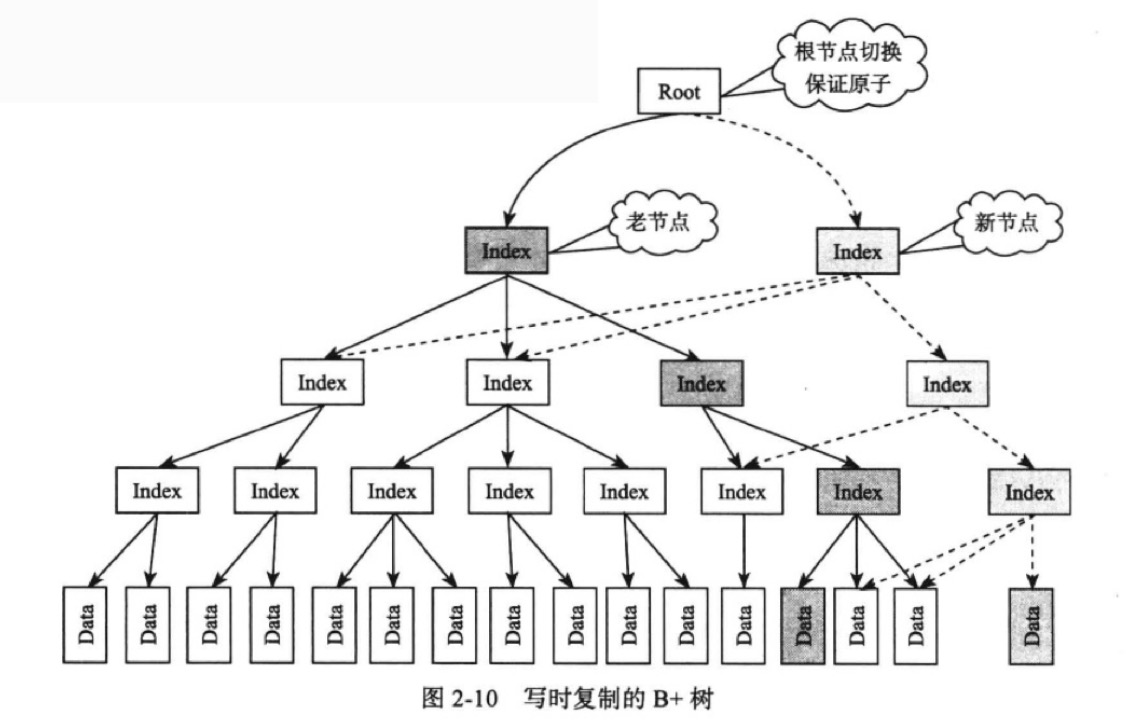
多版本并发控制(MVCC):
是除了写时复制之外另一个实现读事务不加锁的方案。
为每一行数据维护多个版本,无论事务的执行时间多长,都为事务提供事务一开始一致的数据,即当事务开始的时候受影响的这部分数据就独立为一个全新的版本,其他任何事务的执行都无法干扰到这条分支。
InnoDB维护了两个隐藏的列:行被修改的时间、行被删除的时间。这里的时间不是绝对的时间,而是与时间相对应的数据库系统版本号。
每次执行事务的时候都会得到一个递增的版本号,那么事务在执行的时候只需要对比数据原始版本号与自身得到的最新的版本号进行比较然后根据不同的隔离级别来判断是否返回。

但是这样就需要多余的存储开销,且需要定期清除过早的版本号。
故障恢复:
当事务执行到一半的时候系统故障,此时系统重启后需要将事务恢复到最初状体或继续执行下去。(要么commit要么rollback)
数据库系统与其他分布式存储系统一般采用操作日志(有时也被称为提交日志,commit log)技术来实现故障恢复。
操作日志分类:
- 回滚日志(UNDO Log):记录事务修改前的状态
- 重做日志(REDO Log):记录事务修改后的状态
- 回滚/重做日志(UNDO/REDO Log)
操作日志:
为了保证数据库的一致性而采用操作日志,将对数据库的操作持久化到磁盘。如果每执行一次操作就写入磁盘,那么写入的数据是随机写入,每条数据之间都是随机指针;而如果将操作先存入操作日志中,当数量达到一定大小之后/定期统一写入磁盘,那么这次写入磁盘的数据都将是顺序写入。
在操作日志中的写入都是追加写,包括删除操作

事务开始时,先在回滚日志中记录数据的原始状态。
在事务结束后,在重做日志中记录数据的完成状态,并且在回滚/重做日志中记录这个事务操作。
在事务提交后,执行的是REDO日志中的记录,如果是回滚,则执行UNDO日志中的操作,即事务执行完成后写入REDO中,此时尚未提交,也就尚未持久化进磁盘。
针对存储模型可以做的简化:
通过查看mysql的操作日志,可以看到,用户做的所有操作都会被原样记录。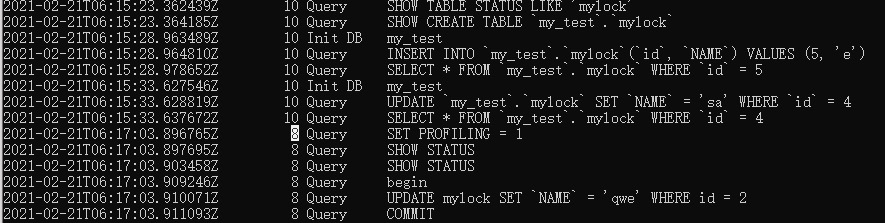
重做日志:
流程如下:
若要进行修复操作,只需要从头到尾读取一遍REDO日志并将其应用到内存中即可。
如果先应用到内存再持久化入磁盘,那么当在内存中修改完成后其他程序就可以立刻读取到相关修改,而此时磁盘还未记录该操作,如果此时系统重启,那么数据恢复后的结果是修改前的数据,但是其他程序已经读取并使用了修改后的数据,这样就造成了数据的不一致性。
优化手段:
成组提交
如果每次执行事务后都立刻写入磁盘会导致系统吞吐量下降,因此系统往往有一个“是否立刻刷入磁盘”的选项,对于一致性要求高的系统可以将其打开。
对于上述情况可以将事务对REDO的记录缓存在内存中,当满足一定条件后统一写入日志中,并在内存中体现数据的更改。这样牺牲了事务的写延时但是能够提高系统的吞吐量。但是这种做法会导致当系统宕机时缓存中还没有写入的事务操作丢失。
说是先保存在内存中,实际上为了防止数据丢失,在每一次写入的时候都要记录到操作日志当中,操作日志与数据块不同。同时为了减少数据丢失的危害,在写入条件部分会特别严格。
当达成以下任何一项条件后写入磁盘:
可以看到写入的条件是十分严格的,精确到毫秒级,可以最大程度地方式数据丢失。
检查点
如果所有的数据都保存在内存中会有两个问题:
类似于索引文件,将内存中的数据结构保存为一个索引文件,系统重启后直接从索引文件构建索引即可,不需要扫描所有数据。
检查点流程如下:
这里应该是如下流程: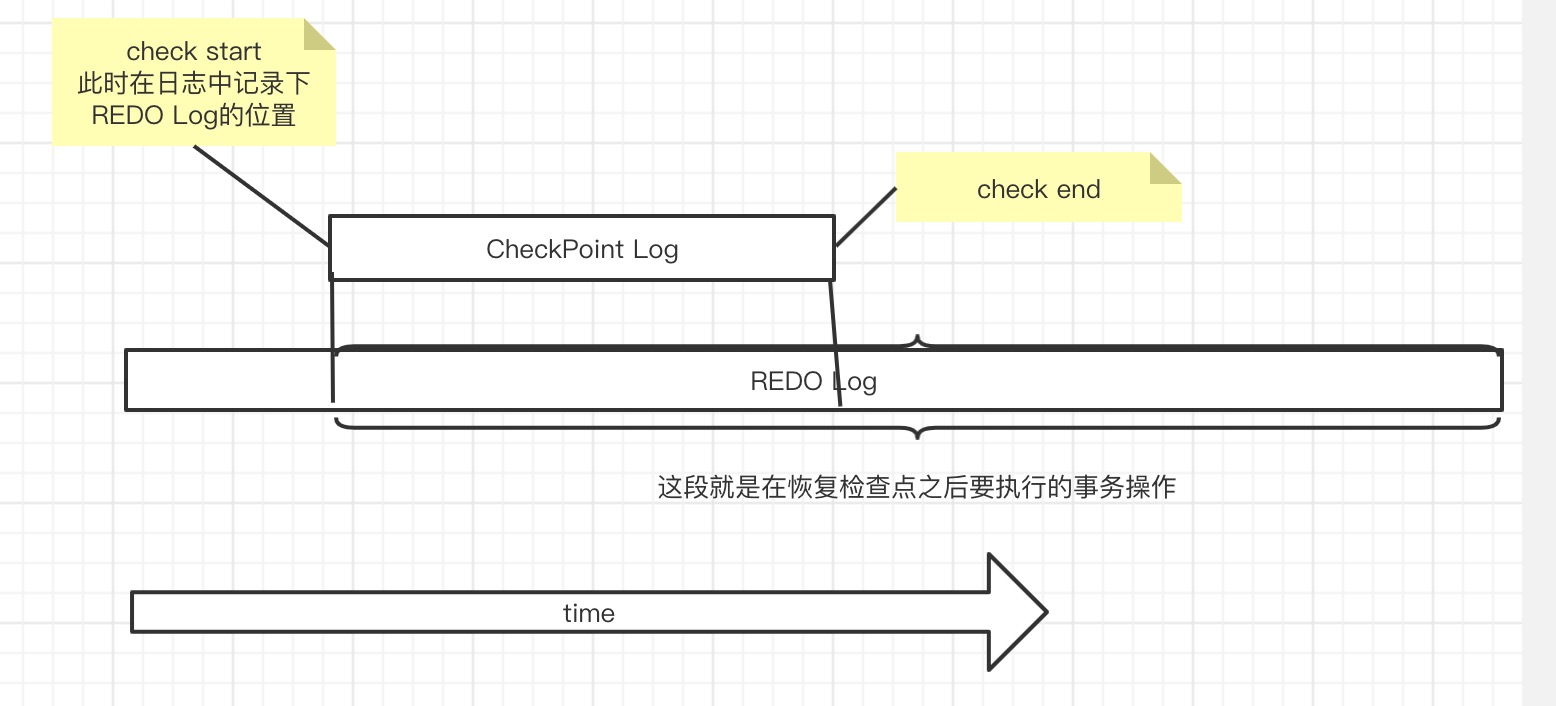
checkpoint保存的是当前内存中数据的状态,可能会有一些修改操作,但由于REDO日志存储的是修改后的结果,就算再执行这些修改操作,数据依旧是以REDO中的为准,不会出现多次执行后结果变化的问题。
加法操作、追加操作不具有冥等性,因此在checkpoint的时候不应该保存这些操作的状态,为此有两种方式:
要么停止服务(进行the world)要么在状态完美的瞬间创建一个快照,持久化的就是这个快照。