索引是帮助Mysql高效获取数据的数据结构。索引可以和数据文件放一起,也可以单独成为一个索引文件。索引通常是B+树结构。
索引的优势和劣势:
优势:
• 可以提高数据检索效率,降低IO成本。
• 通过索引列对数据进行排序,降低排序成本,降低CPU消耗。
○ 对索引列进行order by速度会快很多,因为索引保存的是数据的地址,而单独对索引与数据地址进行排序的开销比对数据进行排序的开销要少很多。
○ 覆盖索引,不需要回表查询。索引列会保存在单独的索引树中,如果要查询的数据在索引树中就存在,则不需要根据数据地址再查询一遍数据。
劣势:
• 索引会占用磁盘空间
• 索引会降低表更新效率,更新数据的同时还要更新索引。
索引的分类:
单列索引:
• 普通索引:Mysql中的基本索引类型,没有限制,允许空值与重复
• 唯一索引:允许为空,但不允许重复
• 主键索引:不允许为空,不允许重复
组合索引:
• 在表的多个字段上创建索引
• 组合索引的使用遵循最左匹配原则
• 一般情况下建议使用组合索引代替单列索引(主键索引除外)
全文索引:
• 只能在CHAR、VARCHAR、TEXT等字段使用
• 只在MyISAM、InnoDB(5.6以后)才能使用
• 优先级最高,不会执行其他索引
空间索引:
• 待补充
索引的存储结构:
• 索引是在存储引擎中实现的,因此不同的存储引擎会使用不同的索引
• MyISAM、InnoDB采用的是B+树索引
B树和B+树的主要区别在于子节点是否存储数据,B+树只在叶子阶段存储数据,且叶子结点都在同一层,并且节点之间通过指针关联
非聚集索引(MyISAM):
• B+树叶子结点存储的是数据行(数据文件)的指针,数据与索引不在一起。
• 非聚集索引包含主键索引和辅助索引都会存储指针的值
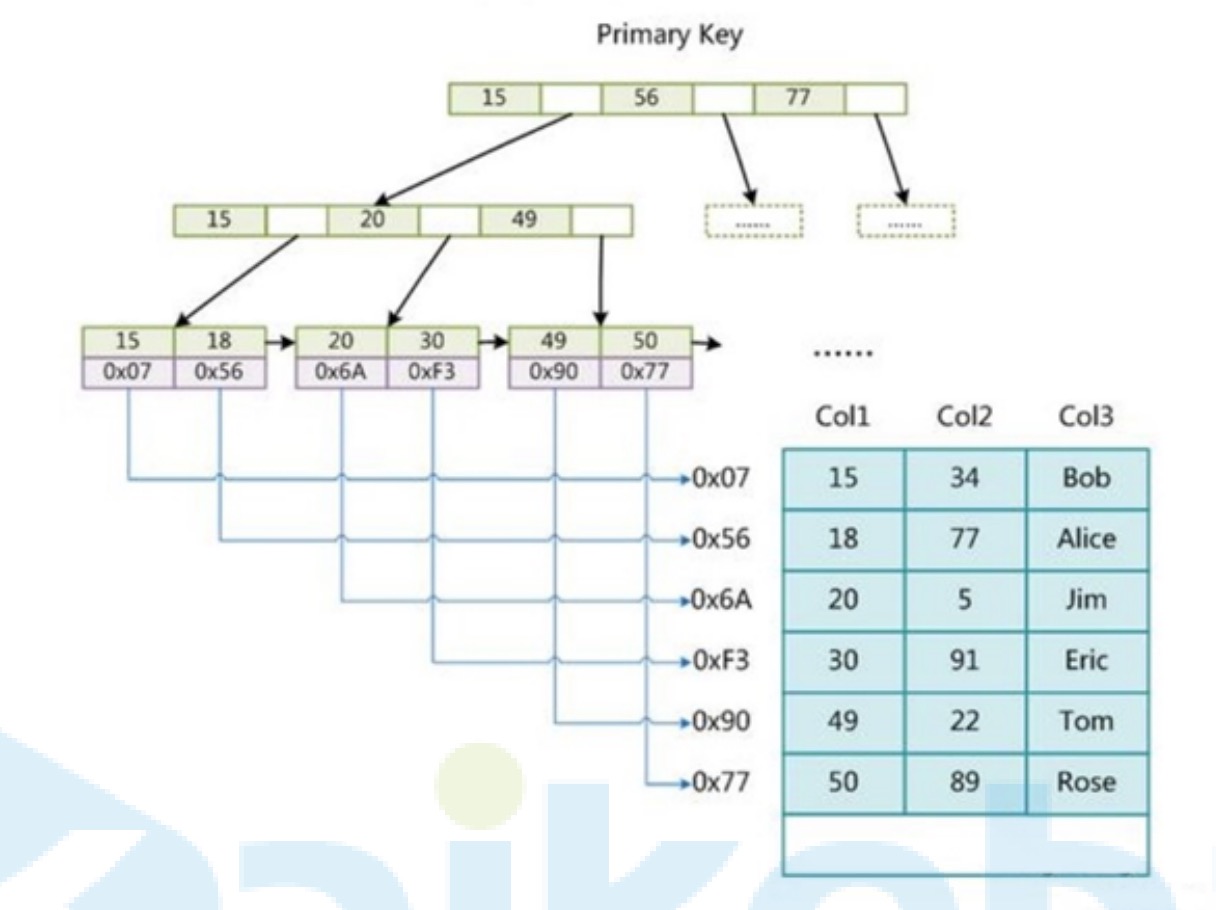
通过主键索引查询到叶子结点后,叶子结点中存储的数据是指向数据行的指针,因此会查询两次。索引文件存储在.mdi中,数据文件存储在.ibd中。
在MyISAN中,主键索引和辅助索引的区别只在于主键索引是唯一的,结构都是一样。
聚集索引(InnoDB):
• 主键索引的叶子结点会存储数据行,即数据和索引是在一起的
• 辅助索引只会存储主键值。如果要用辅助索引查询,则先根据辅助索引获取到主键索引,然后再根据主键索引获取到数据行。
• 如果没有主键,则使用唯一索引建立主键。如果没有唯一索引,则会按照一定规则自动创建主键,类型为长整型。
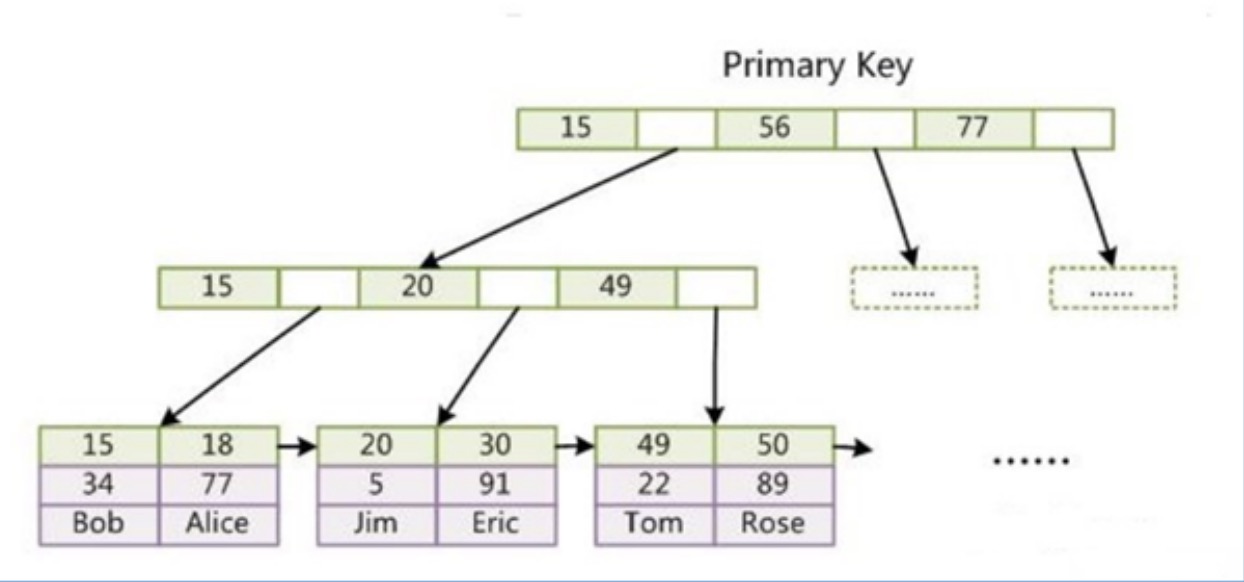
辅助索引保存的是主键的值,即引用主键。因此通过辅助索引查询到主键索引之后还要再根据主键索引查询行数据。这种行为叫做回表查询。
因为辅助索引树保存的数据是索引的列的数据(这部分数据是值,而不是地址),所以如果只是需要查询索引相关的列,则这部分行数据已经存在于辅助索引树中,就不需要回表查询。
例如:table1中id是主键、name是辅助索引、age是一般字段。则他的辅助索引树中保存着id和name的信息。
当:
Select from table1 where name = ‘Bob’ 需要回表查询,因为表示所有数据,但是辅助索引树中只有id和name
Select id,name from table1 where name = ‘Bob’ 此时不需要回表查询,因为id和name的数据都在辅助索引树中就已经存在。
Q:为什么不建议用过长的字段作为主键?
A:因为辅助索引引用的都是主键索引,过长的主键会使得辅助索引树过大。
Q:哪些情况下需要创建索引?
1. 主键自动建立唯一索引
2. 频繁作为查询条件的字段应该创建索引
3. 多表关联查询中,关联字段需要创建索引 on 的两边都是。
4. 查询中排序的字段需要创建索引
5. 频繁查找的字段,创建覆盖索引
6. 查询中统计或者分组的字段应该创建索引 group by
Q:哪些情况下不需要创建索引?
1. 表记录太少
2. 经常进行增删改操作的表
3. 频繁更新的字段
4. where 条件中使用频率不高的字段
组合索引
mysql创建组合索引的规则是首先会对组合索引的最左边第一个字段进行排序,并在此基础在再为第二个索引字段进行排序,类似于order by col1,col2这样的规则。
组合索引相当于将多个列建立成一个辅助索引树,因此比多列创建单列索引更加节省空间。
两者的区别:
• 多列建立一棵索引树更加节省空间
• 多列分别建立索引更容易实现覆盖索引
组合索引使用时遵循最左前缀原则:
• like语句在使用时使用前缀匹配的场合下会使用索引 like ‘a%’
• 当where语句遇到>、<、like、between时中断索引,即当语句where a = 1 and b = 2 and c > 3 and d = 4时,索引在c > 3处结束,不会调用d的索引。此时需要将创建组合索引时的顺序改变即可:将(a,b,c,d)修改为(a,b,d,c),这样在调用语句的时候会自动将d = 4放到c > 3之前。
索引失败:
mysql提供了explain命令对select语句进行分析,并输出直接结果。
explain执行返回的字段说明:
• id: SELECT 查询的标识符. 每个 SELECT 都会自动分配一个唯一的标识符.
• select_type: SELECT 查询的类型.
• table: 查询的是哪个表
• partitions: 匹配的分区
• type: join 类型
• possible_keys: 此次查询中可能选用的索引
• key: 此次查询中确切使用到的索引.
• ref: 哪个字段或常数与 key 一起被使用
• rows: 显示此查询一共扫描了多少行. 这个是一个估计值.
• filtered: 表示此查询条件所过滤的数据的百分比
• extra: 额外的信息
索引失败的几种情况:
• 使用like的时候用后缀匹配,即 like ‘%a’,此时索引失效
• or的前后没有同时使用索引,这里的索引只能是单列索引,如果or前后属于组合所以,则一样无法生效
• 使用组合索引时没有使用第一列索引,导致索引失效。即组合索引是有顺序要求,他会在where条件中根据组合索引创建时的顺序重新排列查询条件,如果不存在第一列索引,则索引失效。
• 数据类型出现隐式转换,如varchar不加单引号会自动转换为int型,使索引失效。
• 在索引字段上使用了not,!=,<>。!=操作不会使用索引,它只会产生全盘扫描。优化方法:将其拆分为 key > 0 or key < 0
• 对索引字段执行计算操作
• 当全盘扫描比使用索引快时mysql会自动使用全盘扫描,此时索引失效。
使用is null,is not null时,依旧会调用索引,mysql在选择是否使用索引时的一个依据就是全盘扫描和使用索引时的开销对比。